
本文转载自旷视研究院。

此篇论文已被 AAAI 2022 收录。
摘 要
RGB-NIR 融合技术可用在极暗环境下增强可见光成像效果。然而现存的融合算法无法处理 RGB-NIR 图像之间的结构不一致问题,从而难以生成高质量的融合结果。本文中,我们对这个难题进行分析,并提出 Dark Vision Net (DVN)来处理结构不一致问题,通过巧妙的网络设计,DVN 将传统算法的核心思想融合进 CNN 框架之中,从而取得了很好的效果。
导 论
对于近红外(Near Infrared,NIR)图像来说, 在人眼不可感知的 NIR 补光灯的帮助下,即使在极端暗光的情况,依然能够保持较高的信噪比。
RGB-NIR 融合技术,正是通过高信噪比的 NIR 图像来大幅提升 RGB 图像信噪比的技术,其能够在使用低成本模组的前提下,取得高成本暗光成像模组才能清晰成像。也正是因此,RGB-NIR 融合技术对很多暗光下的应用有重要意义。
然而,目前的市面上还很少出现利用 RGB-NIR 融合来改善暗光下成像质量的产品。究其原因,我们通过调研发现,目前 RGB-NIR 技术在实际使用中存在的最大技术难题就是极暗光下的 RGB 图像与 NIR 图像之间的结构不一致问题。在 RGB 图像强噪声的影响下,目前的融合算法所生成的融合结果中往往存在非常明显的非自然错误纹理(Artifact),这反而降低了图像质量并严重影响下游任务的效果。

图1 结构不一致问题如何影响融合算法
图 1 中红框标记出现来的区域就是两种常见的 RGB-NIR 结构不一致区域:上方红框展示的是由于油墨涂料本身的物理特性,在 RGB 图像中十分明显的"CODE COMPLETE"在 NIR 图像中却几乎完全消失。下方红框展示的是由于 NIR 补光灯的影响,NIR 图像中往往出现了一些 RGB 图中不存在的"伪影"。从现存融合方法的结果可以看出,现存方法无法处理这种结构不一致问题,会产生明显的非自然错误纹理。下面,我们将现存的融合方法分成两类,分别分析它们无法处理结构不一致问题的原因:
(1)
以 ScaleMap \cite{yan2013cross}为代表的传统融合算法处理噪声干扰的能力有限,因此无用适用于极端暗光环境。对于 ScaleMap 算法来说,十分依赖从原图中提取图像的结构信息(梯度)。再根据专家先验知识来建模 RGB-NIR 图像的结构差异,从而指出哪些区域存在明显的结构不一致性,哪些区域则相反。然而,在极暗光环境下的强噪声使得直接从原图中提取清晰的梯度图变得十分困难。这就使专家先验知识无法能正确的反映出 RGB-NIR 图像之间的梯度不一致性,自然导致传统算法无法输出高质量的融合结果。
(2)以 CUNet\cite{deng2020deep},DKN\cite{kim2021deformable}为代表的基于 CNN 的融合算法也依然无法解决结构不一致问题。虽然凭借CNN 强大表示能力,这类融合算法对于噪声相对不敏感。但是,缺乏了专家先验知识的引导,单纯基于数据驱动的训练方式很难使得 CNN 学习到 RGB-NIR图像之间结构不一致性,使得最终的融合结果在结构不一致的区域会产生明显的非自然错误纹理,非常影响图像的质量。
算法原理
综上所述,既然单独使用专家先验知识和 CNN 都不能处理结构不一致问题,那么为什么不能把它们结合起来使用呢?我们从这个思路出发,我们提出了一个全新的专家先验知识,并设计了一个巧妙的网络结构将这个先验知识引入到RGB-NIR 深度特征的融合过程中,从而兼顾了传统算法和 CNN 类方法的优点,很好地解决了 RGB-NIR 图像之间的梯度不一致问题。
2.1 深度结构
要引入专家先验知识,首先需要解决的技术难题就是如何从低信噪比的图像中提取出清晰的结构信息。我们通过实验发现,类似于 U-Net 的网络在降噪过程中学习到的深度特征本身就包含有丰富的结构信息,我们将这些包含了结构信息的深度特征简称为成为深度结构(Deep Structure)。

图2 深度结构和深度不一致
从图 2 中可以看出,深度结构中不仅包含了丰富的结构信息,还对噪声的干扰十分鲁棒。也正是如此,我们就可以在低信噪比的图片上提取它的深度结构,并在其上引入专家先验知识,对 RGB-NIR 图像之间的结构不一致性进行建模。
2.2 深度不一致先验在深度结构的基础上,我们提出了一个简单却有效的先验知识——深度不一致性先验(DeepInconsistency Prior, 简称为DIP),来建模 RGB-NIR 在结构之间不一致性:
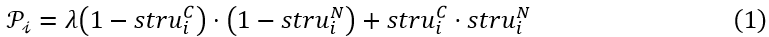
式中, 和 分别代表着从 RGB 图和 NIR 图中提取得到的深度结构的第 i 个通道,其每个像素点的取值范围为$(0,1)$ 代表着该像素位置是否存在明显的边缘; 则代表着计算得到的深度不一致图,其长和宽的尺寸与 , 相同, 每个像素点的取值范围同样为(0,1)。
如图 2 所示,在 与 值差异很大的区域(极端情况下 =1, =0 或者 =0, =1), 的值会接近于 0, 表明这些区域存在明显的 RGB-NIR 结构不一致现象,在后续的融合过程中,不应该从 NIR图像中提取信息来增强 RGB 图像;
而在 与 的值都接近 1 的情况下, 的值同样接近 1,表明这些区域 RGB-NIR 之间的结构基本一致,后续的融合过程中可以更多的从 NIR 图像搬运细节信息来增强 RGB 图像;
剩下的 与 的值都接近0的情况下, 的值为一个超参数 ,这意味着这些区域 RGB-NIR 之间的结构是否一致是不确定的,后续的融合过程中应该有限度地依赖 NIR 图像。超参数 的值一般被设置为 0.5。
技术实现
基于上述的两大技术创新点深度结构和深度不一致先验,我们提出了一个新的RGB-NIR 融合算法 Dark Vision Network (DVN)。DVN 有效地解决了结构不一致性问题,并取得了目前最好的融合效果。

图3 Dark Vision Network 的流程框图。DSEM 指的是深度结构提取模块 (Deep StructureExtraction Module, DSEM)
如图 3 所示,DVN 的流程可以分为两个阶段:
(1)提取深度结构;
(2)深度不一致先验(DIP)引导下的多尺度 RGB-NIR 特征融合。
3.1 提取深度结构因为从 RGB 图像中提取深度结构 的过程与从 NIR 图像中提取 的过程基本一致,我们在下文的描述中不作区分来做统一的表述。
为了从输入图像中提取出深度结构,我们设计了一个深度结构提取模块(Deep Structure Extraction Module,DSEM),其详细网络结构如图 4(a)所示。

图4 重要模块的结构细节
DSEM 首先接受复原子网络 输出的多尺度特征 (i 代表尺度),通过监督学习的方式输出多尺度的深度结构 。其训练所使用的损失函数如下所示:

式中, 是我们为尺度 的深度结构 的所提供的监督信息。我们用一个预训练好的自编码器(AutoEncoder)来获取 , 其详情可见图4(b)。Dist 则代表 Dice 损失。
此外,我们发现在进行特征融合之前对输入 RGB 图像进行降噪可以有效的特征融合效果。同时,为了获取高质量的深度结构 ,RGB 图像的复原子网络 也需要具备初步的降噪能力。因此,DVN 中使用 的输出Coarse-RGB 图来代替 Noisy-RGB 图像输入到接下来特征融合模块。
3.2 DIP 引导下的多尺度特征融合在计算出深度不一致先验知识 之后,我们使用深度不一致性先验 来引导RGB-NIR 的特征融合过程,从而处理结构不一致问题。具体来说,我们首先将 直接作用在 NIR 的深度结构 上,生成一致性 NIR 深度结构 :

在 "特征筛选"的作用下, 与 相比丢弃了结构不一致区域的结构信息。
在获取了 之后, 一个多尺度的 RGB-NIR 特征融合模块将 中的丰富细节信息融合到 RGB 特征中,具体详情可见图 4(c)所示。
实验与讨论

图5 对比结果
图 5 展示了 DVN 的结果与其他对比方法之间的对比。其中 ScaleMap 是最具有代表性的传统 RGB-NIR 融合算法,DKN、CUNet 则是基于深度学习的融合算法,MPRNet 是单 RGB 降噪算法。可以很明显的看出,相比其他所有的对比算法,DVN 在不仅有效地对噪声进行了抑制,也良好地恢复了 RGB 图像中的细节细节。同时,DVN 的融合结果中也并不包含由于 RGB-NIR 之间结构不一致问题所导致的非自然错误纹理。
参考文献
[1] Q. Yan, X. Shen, L. Xu, S. Zhuo, X. Zhang, L. Shen, and J. Jia, “Cross-field joint image restoration via scale map,” in Proceedings of the IEEE International Conference on Computer Vision, pp. 1537–1544, 2013.
[2] X. Deng and P. L. Dragotti, “Deep convolutional neural network for multi-modal image restoration and fusion,” IEEE transactions on pattern analysis and machine intelligence, 2020.
[3] B. Kim, J. Ponce, and B. Ham, “Deformable kernel networks for joint image filtering,” International Journal of Computer Vision, vol. 129, no. 2, pp. 579–600, 2021.
[4] R. Deng, C. Shen, S. Liu, H. Wang, and X. Liu, “Learning to predict crisp boundaries,” in Proceedings of the European Conference on Computer Vision (ECCV), pp. 562–578, 2018.
[5] S. W. Zamir, A. Arora, S. Khan, M. Hayat, F. S. Khan, M.-H. Yang, and L. Shao, “Multi-stage progressive image restoration,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 14821–14831, 2021.
备注:作者也是我们「3D视觉从入门到精通」特邀嘉宾:一个超干货的3D视觉学习社区
本文仅做学术分享,如有侵权,请联系删文。
3D视觉工坊精品课程官网:3dcver.com
1.面向自动驾驶领域的多传感器数据融合技术
2.面向自动驾驶领域的3D点云目标检测全栈学习路线!(单模态+多模态/数据+代码) 3.彻底搞透视觉三维重建:原理剖析、代码讲解、及优化改进 4.国内首个面向工业级实战的点云处理课程 5.激光-视觉-IMU-GPS融合SLAM算法梳理和代码讲解 6.彻底搞懂视觉-惯性SLAM:基于VINS-Fusion正式开课啦 7.彻底搞懂基于LOAM框架的3D激光SLAM: 源码剖析到算法优化 8.彻底剖析室内、室外激光SLAM关键算法原理、代码和实战(cartographer+LOAM +LIO-SAM)
9.从零搭建一套结构光3D重建系统[理论+源码+实践]
10.单目深度估计方法:算法梳理与代码实现
11.自动驾驶中的深度学习模型部署实战
12.相机模型与标定(单目+双目+鱼眼)
13.重磅!四旋翼飞行器:算法与实战
14.ROS2从入门到精通:理论与实战
重磅!3DCVer-学术论文写作投稿 交流群已成立
扫码添加小助手微信,可申请加入3D视觉工坊-学术论文写作与投稿 微信交流群,旨在交流顶会、顶刊、SCI、EI等写作与投稿事宜。
同时也可申请加入我们的细分方向交流群,目前主要有3D视觉、CV&深度学习、SLAM、三维重建、点云后处理、自动驾驶、多传感器融合、CV入门、三维测量、VR/AR、3D人脸识别、医疗影像、缺陷检测、行人重识别、目标跟踪、视觉产品落地、视觉竞赛、车牌识别、硬件选型、学术交流、求职交流、ORB-SLAM系列源码交流、深度估计等微信群。
一定要备注:研究方向+学校/公司+昵称,例如:”3D视觉 + 上海交大 + 静静“。请按照格式备注,可快速被通过且邀请进群。原创投稿也请联系。

▲长按加微信群或投稿

▲长按关注公众号
3D视觉从入门到精通知识星球:针对3D视觉领域的视频课程(三维重建系列、三维点云系列、结构光系列、手眼标定、相机标定、激光/视觉SLAM、自动驾驶等)、知识点汇总、入门进阶学习路线、最新paper分享、疑问解答五个方面进行深耕,更有各类大厂的算法工程人员进行技术指导。与此同时,星球将联合知名企业发布3D视觉相关算法开发岗位以及项目对接信息,打造成集技术与就业为一体的铁杆粉丝聚集区,近4000星球成员为创造更好的AI世界共同进步,知识星球入口:
学习3D视觉核心技术,扫描查看介绍,3天内无条件退款

圈里有高质量教程资料、答疑解惑、助你高效解决问题
觉得有用,麻烦给个赞和在看~

