点击上方“3D视觉工坊”,选择“星标”
干货第一时间送达

作者丨paopaoslam
来源丨泡泡机器人SLAM
标题:MSC-VO: Exploiting Manhattan and Structural Constraints for Visual Odometry
作者:Joan P. Company-Corcoles, Emilio Garcia-Fidalgo and Alberto Ortiz
来源:CVPR 2021
编译:廖邦彦
审核:阮建源 王志勇

摘要

视觉里程计算法在面对低纹理场景时,往往会退化。例如,人造环境往往很难找到足够数量的点特征。而其他的几何视觉线索,如线,通常可以在这些场景中找到,可以变得特别有用。此外,这些场景通常表现出结构规律,如平行性或正交性,满足曼哈顿世界的假设。在此前提下,在本工作中,我们介绍了MSC-VO,一种基于rgb-d的视觉里程计方法,它结合了点和线特征,如果存在,可以利用这些结构规正和场景的曼哈顿轴。在我们的方法中,这些结构约束最初被用来准确地估计提取的线的三维位置。这些约束还与估计的曼哈顿轴和点和线的重投影误差相结合,通过局部地图优化来细化相机姿态。这种组合使我们的方法即使在没有上述约束的情况下也能够运行,从而允许该方法在更广泛的场景中工作。此外,我们提出了一种新的主要依赖于线特征的多视点曼哈顿轴估计方法。MSC-VO使用几个公共数据集进行评估,性能优于其他最先进的解决方案,甚至于与一些SLAM方法比较不相上下。

Motivation

-
大多数vo slam方法依赖于点特征来实现,但是在低纹理区域,容易退化。使用点和线特征能够降低跟踪的失败。
-
使用曼哈顿世界假设的slam方法并没有考虑在室内环境中,该假设无法严格成立,容易导致跟踪失败
-
同时,大多数工作依赖平面来检测并且跟踪曼哈顿主轴,但是这意味着更高的计算用时
-
本文利用点和线特征结合几何约束和MA对齐,提出了一个新的RGB-DVO框架

Contribution

-
一种鲁棒的针对低纹理环境的RGB-DVO框架,可以在场景中存在结构规律和MA对齐时提高姿态精度。否则,我们的解决方案仍然可以运行,这将在实验结果部分中显示。
-
一种基于场景中所呈现的结构信息的三维线端点计算方法。
-
一种精确、高效的三维局部地图优化策略,它将重投影误差与结构约束和MA对齐相结合。
-
一种新颖的MA初始化过程,通过在多图非线性最小二乘公式中使用多帧观测来改进传统采用的平均位移算法的估计。
-
在几个公共数据集上对所提出的方法进行了广泛的评估,并与其他VO和SLAM最先进的方法进行了比较。
-
作为额外的贡献,源代码MSC-VO开源 http://github.com/joanpepcompany/MSC-VO。

方法概述

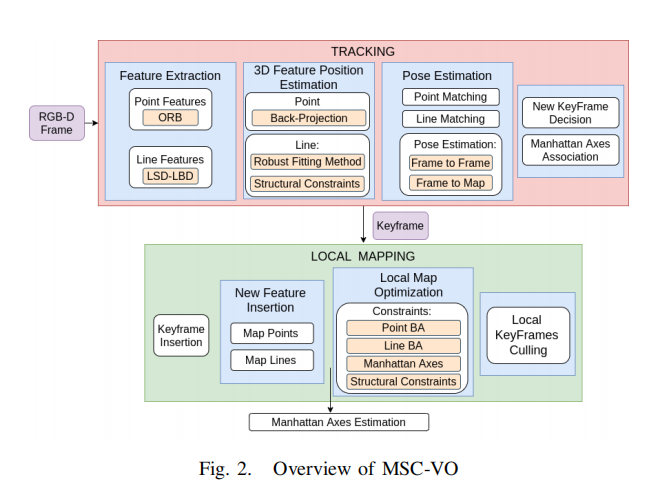
Tracking
跟踪线程负责估计所捕获的每一帧的位置。此外,该模块还可以决定是否需要创建一个新的关键帧。如果可能的话,它还将每条新的地图线与其中一个MA关联起来。
1) Feature Extraction:
点特征通过ORB检测并且描述,线特征通过LSD检测并且使用LBD描述子描述,在之后,我们使用p_i来表示点特征在图像的坐标,使用线段起点s_j和终点e_j来表示。最后,归一化线段l_j通过下式表示
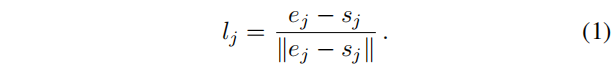
2) 3D Feature Position Estimation:
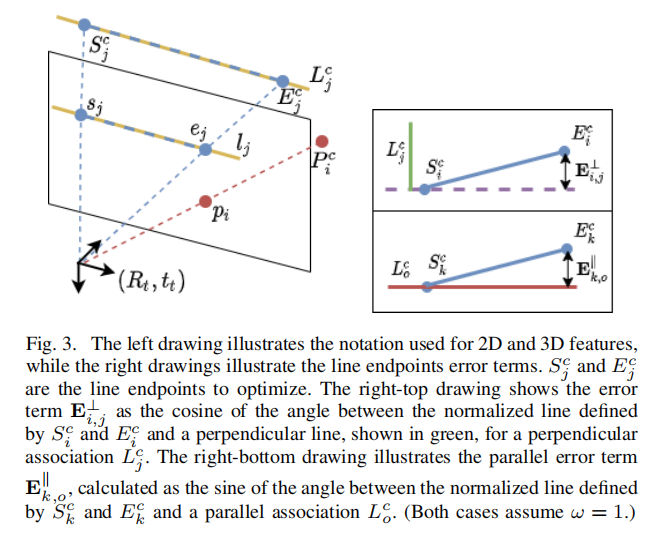
将点特征逆投影到相机坐标系,但是对于线特征,由于线比点更受深度不连续和遮挡的影响,这个简单的过程可能会导致不准确的3D线。为了减少这种影响,我们提出了一种鲁棒的两步方法来计算三维线端点。首先,对于每一个线段,我们计算其结束点的初始三维位置,表示为{Sjc,Ejc},通过反向投影符合图像中直线的点的子集,然后,执行如[14]中的鲁棒拟合步骤。三维归一化线Lcj的计算方法与公式1相似。接下来,我们使用场景的结构约束来细化每个检测到的线。我们从关联好的平行的和垂线开始。为此,对于在当前图像中检测到的每一对可能的线(Lcm,Lcn),我们通过点积计算两个方向向量之间的夹角的余弦
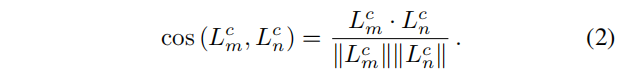
我们只选择那些余弦数值靠近0或者1的那些线段对,分别表示了垂直和平行的线。我们定义了旋转误差d为

当将垂直线和平行线分开后,我们分别定义垂直和平行误差项
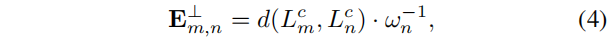

其中的wn定义为从LSD返回的权重项,最后误差方程定义为
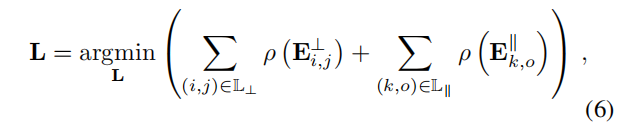
3) Pose Estimation:
一旦提取出特征,就进行优化程序来估计当前的相机方向R和平移t。首先,在前一帧中观察到的地图点和线被投影到当前帧中,假设是一个恒速运动模型。接下来,计算两组2D-3D对应项,一组用于[2]中的点,另一组用于[5]中的线。然后使用这些关联来优化当前的相机姿态,最小化以下成本函数
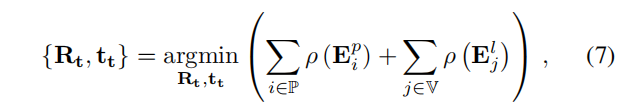
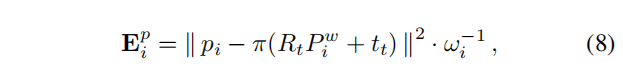
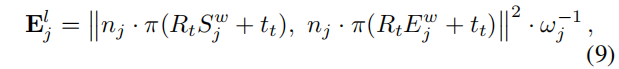
4) Keyframe Insertion:
我们使用了与ORB-SLAM2类似的策略,但同时考虑了线段匹配。与ORB-SLAM2不同,我们不使用跟踪的最少数量的条件。这一想法背后的基本原理是,所提出的方法专注于低纹理环境,通常每帧跟踪的特征数量可以在场景之间发生巨大变化。因此,不可能确定一个合理的阈值。相反,我们建议使用在地图中被跟踪的当前帧特征与这些特征与可能创建的特征的总和之间的比率。一旦生成了一个新的关键帧,点和线将包含在本地地图中,并挑选冗余的特征,正如在[2]中执行的那样。对于每条新的地图线段,我们在局部地图中搜索平行或垂直的线对应关系。此外,如果可能的话,每一行还与一个MA相关联,如下一节所述。
5) Manhattan Axes Association:
当一个新关键帧被加入了,对于每个新的地图线,我们将其与每个曼哈顿轴进行比较,如果他们在公式3中的数值离1足够近,则认为平行于曼哈顿轴。这些关联用于局部地图优化,以减少相机的旋转漂移。请注意,考虑到结构约束和这种MA对齐的组合,我们的方法能够在这些轴不可用的情况下运行。
Local Mapping
1) Local Map Optimization:
延续使用ORBSLAM2中的共视图局部优化策略来优化位姿和地图点以及地图线
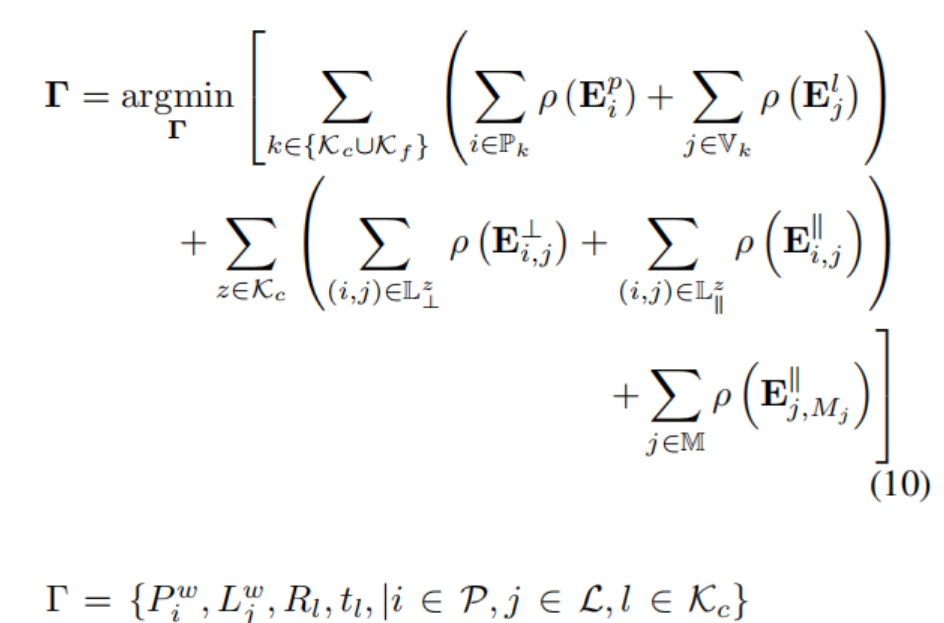
其中的误差项分别由公式8,9,4,5,5定义得到。
2) Manhattan Axes Estimation:
本文提出了一种从粗到细的MA估计策略,其中最粗糙的估计扩展了Kim等人的工作[10]。然后,通过考虑沿着不同关键帧的多线观察来细化估计的MA。我们通过下式的多关键帧观测来细化估计的曼哈顿轴方向。
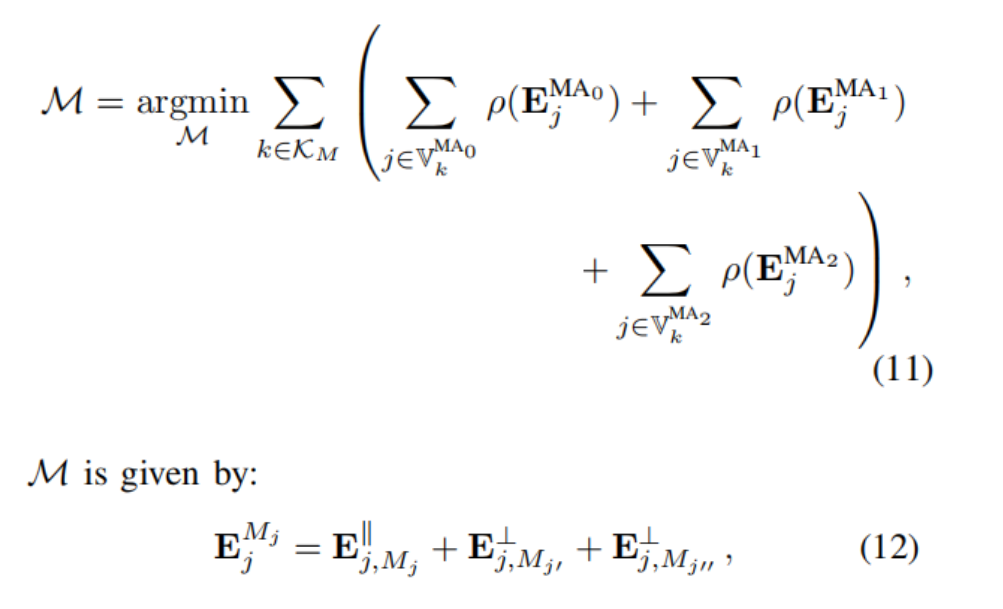

实验结果



Abstract
Visual odometry algorithms tend to degrade when facing low-textured scenes —from e.g. human-made environments—, where it is often difficult to find a sufficient number of point features. Alternative geometrical visual cues, such as lines, which can often be found within these scenarios, can become particularly useful. Moreover, these scenarios typically present structural regularities, such as parallelism or orthogonality, and hold the Manhattan World assumption. Under these premises, in this work, we introduce MSC-VO, an RGB-D -based visual odometry approach that combines both point and line features and leverages, if exist, those structural regularities and the Manhattan axes of the scene. Within our approach, these structural constraints are initially used to estimate accurately the 3D position of the extracted lines. These constraints are also combined next with the estimated Manhattan axes and the reprojection errors of points and lines to refine the camera pose by means of local map optimization. Such a combination enables our approach to operate even in the absence of the aforementioned constraints, allowing the method to work for a wider variety of scenarios. Furthermore, we propose a novel multi-view Manhattan axes estimation procedure that mainly relies on line features. MSC-VO is assessed using several public datasets, outperforming other state-of-the-art solutions, and comparing favourably even with some SLAM methods.
本文仅做学术分享,如有侵权,请联系删文。
3D视觉工坊精品课程官网:3dcver.com
1.面向自动驾驶领域的多传感器数据融合技术
2.面向自动驾驶领域的3D点云目标检测全栈学习路线!(单模态+多模态/数据+代码) 3.彻底搞透视觉三维重建:原理剖析、代码讲解、及优化改进 4.国内首个面向工业级实战的点云处理课程 5.激光-视觉-IMU-GPS融合SLAM算法梳理和代码讲解 6.彻底搞懂视觉-惯性SLAM:基于VINS-Fusion正式开课啦 7.彻底搞懂基于LOAM框架的3D激光SLAM: 源码剖析到算法优化 8.彻底剖析室内、室外激光SLAM关键算法原理、代码和实战(cartographer+LOAM +LIO-SAM)
9.从零搭建一套结构光3D重建系统[理论+源码+实践]
10.单目深度估计方法:算法梳理与代码实现
11.自动驾驶中的深度学习模型部署实战
12.相机模型与标定(单目+双目+鱼眼)
13.重磅!四旋翼飞行器:算法与实战
14.ROS2从入门到精通:理论与实战
15.国内首个3D缺陷检测教程:理论、源码与实战
重磅!3DCVer-学术论文写作投稿 交流群已成立
扫码添加小助手微信,可申请加入3D视觉工坊-学术论文写作与投稿 微信交流群,旨在交流顶会、顶刊、SCI、EI等写作与投稿事宜。
同时也可申请加入我们的细分方向交流群,目前主要有3D视觉、CV&深度学习、SLAM、三维重建、点云后处理、自动驾驶、多传感器融合、CV入门、三维测量、VR/AR、3D人脸识别、医疗影像、缺陷检测、行人重识别、目标跟踪、视觉产品落地、视觉竞赛、车牌识别、硬件选型、学术交流、求职交流、ORB-SLAM系列源码交流、深度估计等微信群。
一定要备注:研究方向+学校/公司+昵称,例如:”3D视觉 + 上海交大 + 静静“。请按照格式备注,可快速被通过且邀请进群。原创投稿也请联系。

▲长按加微信群或投稿

▲长按关注公众号
3D视觉从入门到精通知识星球:针对3D视觉领域的视频课程(三维重建系列、三维点云系列、结构光系列、手眼标定、相机标定、激光/视觉SLAM、自动驾驶等)、知识点汇总、入门进阶学习路线、最新paper分享、疑问解答五个方面进行深耕,更有各类大厂的算法工程人员进行技术指导。与此同时,星球将联合知名企业发布3D视觉相关算法开发岗位以及项目对接信息,打造成集技术与就业为一体的铁杆粉丝聚集区,近4000星球成员为创造更好的AI世界共同进步,知识星球入口:
学习3D视觉核心技术,扫描查看介绍,3天内无条件退款

圈里有高质量教程资料、答疑解惑、助你高效解决问题
觉得有用,麻烦给个赞和在看~


