点击上方“3D视觉工坊”,选择“星标”
干货第一时间送达

作者丨Rubin
来源丨计算机视觉CV
最近在github上看到一个博主开源的YOLOv7仓库都惊呆了,YOLOv6都还没出来怎么就到YOLOv7了 稍微看了下,原来作者是基于这两年来很火的transformer做的检测和分割模型,测试的效果都非常棒,比YOLOv5效果好很多。由此可见,基于Transformer based的检测模型才是未来。你会发现它学到的东西非常合理,比从一大堆boudingbox里面选择概率的范式要好一点。话不多说,先上代码链接:
稍微看了下,原来作者是基于这两年来很火的transformer做的检测和分割模型,测试的效果都非常棒,比YOLOv5效果好很多。由此可见,基于Transformer based的检测模型才是未来。你会发现它学到的东西非常合理,比从一大堆boudingbox里面选择概率的范式要好一点。话不多说,先上代码链接:
https://github.com/jinfagang/yolov7

开源的YOLOv7功能很强大,支持 YOLO, DETR, AnchorDETR等等。作者声称发现很多开源检测框架,比如YOLOv5、EfficientDetection都有自己的弱点。例如,YOLOv5实际上设计过度,太多混乱的代码。更令人惊讶的是,pytorch中至少有20多个不同版本的YOLOv3-YOLOv4的重新实现,其中99.99%是完全错误的,你既不能训练你的数据集,也不能使其与原paper相比。所以有了作者开源的这个仓库!该repo 支持DETR等模型的ONNX导出,并且可以进行tensorrt推理。
该repo提供了以下的工作:
-
YOLOv4 contained with CSP-Darknet53;
-
YOLOv7 arch with resnets backbone;
-
GridMask augmentation from PP-YOLO included;
-
Mosiac transform supported with a custom datasetmapper;
-
YOLOv7 arch Swin-Transformer support (higher accuracy but lower speed);
-
RandomColorDistortion, RandomExpand, RandomCrop, RandomFlip;
-
CIoU loss (DIoU, GIoU) and label smoothing (from YOLOv5 & YOLOv4);
-
YOLOv7 Res2net + FPN supported;
-
Pyramid Vision Transformer v2 (PVTv2) supported
-
YOLOX s,m,l backbone and PAFPN added, we have a new combination of YOLOX backbone and pafpn;
-
YOLOv7 with Res2Net-v1d backbone, we found res2net-v1d have a better accuracy then darknet53;
-
Added PPYOLOv2 PAN neck with SPP and dropblock;
-
YOLOX arch added, now you can train YOLOX model (anchor free yolo) as well;
-
DETR: transformer based detection model and onnx export supported, as well as TensorRT acceleration;
-
AnchorDETR: Faster converge version of detr, now supported!
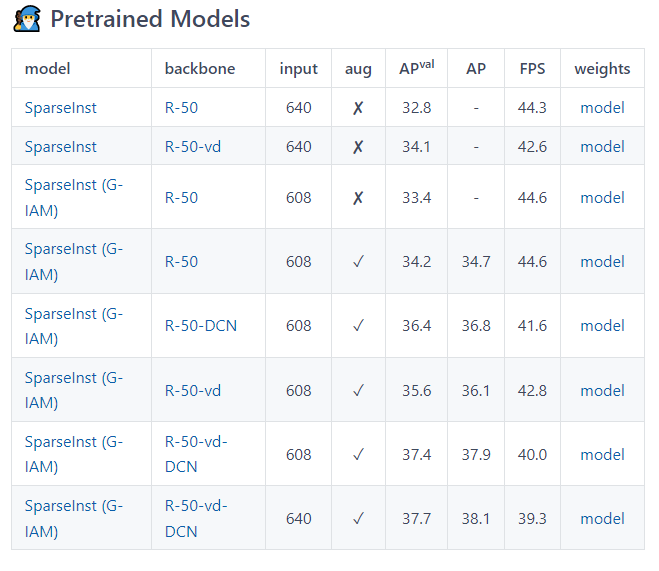
仓库提供了快速检测Quick start和train自己数据集的代码及操作流程,也提供了许多预训练模型可供下载,读者可依据自己的需要选择下载对应的检测模型。
python3 demo.py --config-file configs/wearmask/darknet53.yaml --input ./datasets/wearmask/images/val2017 --opts MODEL.WEIGHTS output/model_0009999.pth实例分割
python demo.py --config-file configs/coco/sparseinst/sparse_inst_r50vd_giam_aug.yaml --video-input ~/Movies/Videos/86277963_nb2-1-80.flv -c 0.4 --opts MODEL.WEIGHTS weights/sparse_inst_r50vd_giam_aug_8bc5b3.pth基于detectron2新推出的LazyConfig系统,使用LazyConfig模型运行
python3 demo_lazyconfig.py --config-file configs/new_baselines/panoptic_fpn_regnetx_0.4g.py --opts train.init_checkpoint=output/model_0004999.pth训练数据集
python train_net.py --config-file configs/coco/darknet53.yaml --num-gpus 1
如果你想训练YOLOX,使用 config file configs/coco/yolox_s.yaml
导出 ONNX && TensorRT && TVM detrpython export_onnx.py --config-file detr/config/fileSparseInst
python export_onnx.py --config-file configs/coco/sparseinst/sparse_inst_r50_giam_aug.yaml --video-input ~/Videos/a.flv --opts MODEL.WEIGHTS weights/sparse_inst_r50_giam_aug_2b7d68.pth INPUT.MIN_SIZE_TEST 512
具体的操作流程可以去原仓库看,都有详细的解析!
检测结果



[1]https://manaai.cn/aisolution_detail.html?id=7
[2]https://github.com/jinfagang/yolov7
本文仅做学术分享,如有侵权,请联系删文。
3D视觉工坊精品课程官网:3dcver.com
1.面向自动驾驶领域的多传感器数据融合技术
2.面向自动驾驶领域的3D点云目标检测全栈学习路线!(单模态+多模态/数据+代码) 3.彻底搞透视觉三维重建:原理剖析、代码讲解、及优化改进 4.国内首个面向工业级实战的点云处理课程 5.激光-视觉-IMU-GPS融合SLAM算法梳理和代码讲解 6.彻底搞懂视觉-惯性SLAM:基于VINS-Fusion正式开课啦 7.彻底搞懂基于LOAM框架的3D激光SLAM: 源码剖析到算法优化 8.彻底剖析室内、室外激光SLAM关键算法原理、代码和实战(cartographer+LOAM +LIO-SAM)
9.从零搭建一套结构光3D重建系统[理论+源码+实践]
10.单目深度估计方法:算法梳理与代码实现
11.自动驾驶中的深度学习模型部署实战
12.相机模型与标定(单目+双目+鱼眼)
13.重磅!四旋翼飞行器:算法与实战
14.ROS2从入门到精通:理论与实战
15.国内首个3D缺陷检测教程:理论、源码与实战
重磅!3DCVer-学术论文写作投稿 交流群已成立
扫码添加小助手微信,可申请加入3D视觉工坊-学术论文写作与投稿 微信交流群,旨在交流顶会、顶刊、SCI、EI等写作与投稿事宜。
同时也可申请加入我们的细分方向交流群,目前主要有3D视觉、CV&深度学习、SLAM、三维重建、点云后处理、自动驾驶、多传感器融合、CV入门、三维测量、VR/AR、3D人脸识别、医疗影像、缺陷检测、行人重识别、目标跟踪、视觉产品落地、视觉竞赛、车牌识别、硬件选型、学术交流、求职交流、ORB-SLAM系列源码交流、深度估计等微信群。
一定要备注:研究方向+学校/公司+昵称,例如:”3D视觉 + 上海交大 + 静静“。请按照格式备注,可快速被通过且邀请进群。原创投稿也请联系。

▲长按加微信群或投稿

▲长按关注公众号
3D视觉从入门到精通知识星球:针对3D视觉领域的视频课程(三维重建系列、三维点云系列、结构光系列、手眼标定、相机标定、激光/视觉SLAM、自动驾驶等)、知识点汇总、入门进阶学习路线、最新paper分享、疑问解答五个方面进行深耕,更有各类大厂的算法工程人员进行技术指导。与此同时,星球将联合知名企业发布3D视觉相关算法开发岗位以及项目对接信息,打造成集技术与就业为一体的铁杆粉丝聚集区,近4000星球成员为创造更好的AI世界共同进步,知识星球入口:
学习3D视觉核心技术,扫描查看介绍,3天内无条件退款

圈里有高质量教程资料、答疑解惑、助你高效解决问题
觉得有用,麻烦给个赞和在看~


