点击上方“3D视觉工坊”,选择“星标”
干货第一时间送达

来源丨人脸人体重建

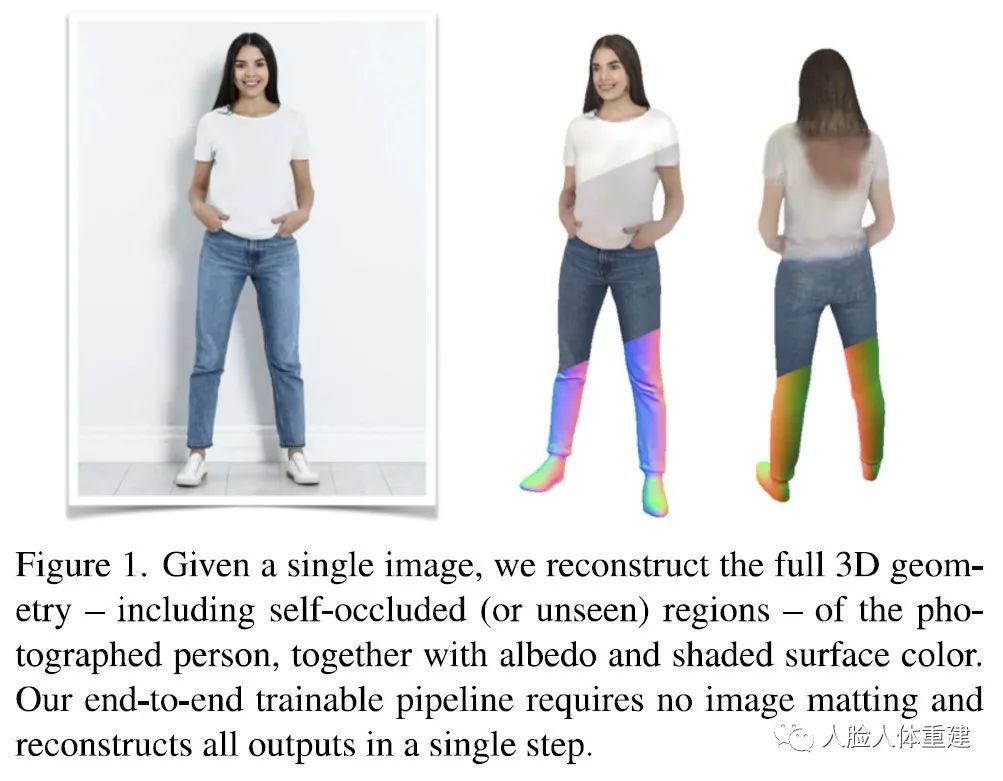
本文作者均来自 Google Research,作者提出了一个新颖的端到端的深度神经网络来从单张彩色图片重建具有真实感的穿着衣服的人体 3D 模型。
从单张图片重建人体的 3D 模型是近几年来的一个研究热点,出现了诸如 PIFu、PIFuHD、PAMIR、ARCH、ARCH++ 等众多优秀方法,但这些方法都存在一些问题,首先这些方法预测的人体外观都包含光照信息,有些方法根本不生成颜色信息,这样重建的模型就无法真实地放置在虚拟场景中。此外,许多方法都包含多个步骤,需要先计算一些中间表示,这就给计算和内存提出了更高要求。在大多数现有方法中,颜色都是在几何之后的步骤估计的,但从方法论的角度来看,本文作者认为应该同时计算几何形状和表面颜色,因为阴影 (shading) 是表面几何的一个强有力的线索,且无法解耦。
考虑到当前方法的这些缺点,作者提出了 PHORHUM,一个端到端的解决方案,通过一个深度神经网络同时预测人体的几何和外观。外观使用不带场景光照的反照率 (albedo) 颜色作为外观表达,此外,文章方法还能预测场景光照,使得光照和颜色的解耦变得可能。此外,作者发现使用稀疏的 3D 信息作为监督会得到不够真实地结果,为此作者引入了渲染损失来提高预测的外观的质量。文章的贡献主要在以下几点:
-
提出了一个端到端的高质量人体重建方法,能够取得比当前 SOTA 更加准确、更多细节的重建结果;
-
首次计算出人体的 albedo 和 shading 信息;
-
提出了渲染损失,极大地改善了预测的外观的真实性。
总的来说,PHORHUM 使用透视相机模型、无需去除背景、能够重建反照率、能够估计光照,只需一个人体检测器,裁剪出人体部分送入网络便可得到重建结果。
下面表格展示了文章方法与当前众多方法的对比

主页:https://phorhum.github.io/
Method
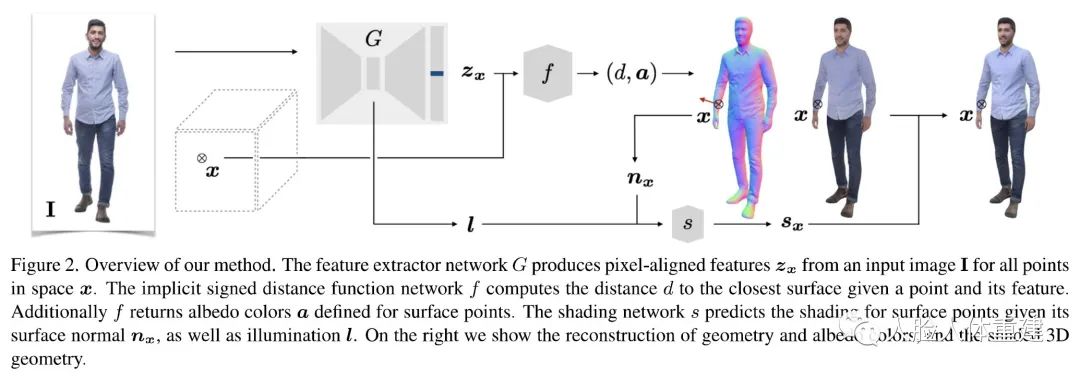
文章方法的流程如下图所示,给定一张输入图片 ,首先通过特征提取网络 为空间中的每个点 生成像素对齐的特征 , 然后隐式函数网络 根据空间中点 的位置和特征预测其到人体表面的距离 和 albedo 颜色 ,shading 网络 从表面法向 和光照 预测点的 shading 信息。图中右面三幅图分别展示了重建的几何、albedo 颜色和着色后的几何。
作者使用神经网络 MLP 表示的符号距离函数 (SDF) 的零等值面表示人体表面 :
其中 是所有可学习参数的集合,曲面 被像素对齐特征 参数化:
这里 是像素的双线性插值, 是使用相机 将点 投影得到的像素位置 (作者使用固定焦距的透视相机模型)。 返回点 相对于曲面 的符号距离 和 albedo 颜色 :
表示位置编码[2],其将 映射到高维空间,以让 MLP 能够学习到更多的高频信息 (跟 NeRF 中类似)。
为了让网络能够对 shading 和 albedo 解耦,作者使用额外的神经网络预测每个点处的 shading:
这里 是由估计的符号距离的梯度定义的表面法向, 是从图片估计的光照,来自特征提取网络 的 bottleneck layer,最终着色的颜色即为 ,其中 表示逐元素相乘。
Losses
损失函数主要包含三部分,几何损失、颜色损失和渲染损失。
Geometry Losses作者从网格表面 采样点集 并让这些点离表面的距离趋于零,距离的梯度接近真实曲面的法向:
此外,对非网格表面的其余采样点 监督其到位于曲面内外的符号:
这里 是内部、外部标签, 是 sigmoid 函数, 是二元交叉熵。 决定了决策边界的锐度,并且是可学习的。作者还增加了几何正则化损失,使得 在任何地方都逼近一个梯度范数为 1 的
402 Payment Required Color Losses作者使用从网格纹理计算的反照率的真实值 来监督反照率颜色:
402 Payment Required跟 PIFu 类似,作者不仅在表面上而且在表面附近计算 。由于反照率仅在表面上定义,作者使用表面上最近邻点的反照率作为表面附近点的反照率的近似。
Rendering Losses虽然几何损失和颜色损失对于网络训练已经足够,但作者发现渲染损失有助于进一步限制问题并提高结果的视觉保真度。为此,在训练期间,作者使用光线追踪以随机步长渲染表面 的固定大小的随机图像块。首先计算由相机 决定的对应于图像块的射线 ,然后使用两个策略追踪表面。首先,为了确定是否可以沿着一条射线定位一个表面,沿着每条射线 以相等的采样距离计算采样点到表面距离的符号
这里 是相机位置。然后选择同时满足 和 ( 是由图像分割 mask 计算的像素的内/外标签) 的射线集合 ,即最终选择的射线 located a surface where a surface is expected。对于子集 中的射线,作者使用 sphere tracing 来精确定位表面,参考[3],作者让第 次迭代处的交点 相对于网络参数可微,而不必存储 sphere tracing 的梯度:
在实际实现时,作者从两个方向追踪曲面,从相机出发到场景和从无穷远出发到相机,即同时定位曲面的正面点 和背面点 。渲染损失的定义如下:
这里反照率的真实值 来自渲染的未着色的图片 和 。背面图像 展示了模型的背面,是通过在渲染期间反转深度缓冲区生成的。此外,作者还在渲染的正面、背面图像块上定义了 VGG 损失 ,使得渲染的图片与未着色的真实图像有着相似的结构。最后,作者使用下面损失监督 shading 信息:
其中 是射线 对应的图像 中像素颜色,即 albedo 乘以 shading 应该跟图像中的颜色接近。作者还发现使用图像中的所有像素 对应的真实的法向量 和反照率 对于 shading 信息的监督也很有用:
402 Payment Required下图展示了渲染损失对于反照率预测的作用,能够显著提高预测的准确性和逼真度。

整个网络训练的损失函数即为上面介绍的损失的加权组合:
402 Payment RequiredDataset
作者使用的训练数据来自包含不同站立姿势、穿着各种服装、有时提着包或拿着小物件的 217 个人体扫描数据,并对 100 个扫描数据的服装颜色进行了数据增强,对 38 个扫描数据进行了重新姿态化。对于每个模型,作者采用高动态范围图像 (HDRI) 来实现逼真的基于图像的照明和作为背景。对于每个模型,渲染 shaded 图像、正面和背面的反照率图像、法向图、alpha mask,下面展示了一个样例。作者使用随机的高动态范围图像和人体姿态,一共渲染了大约 19 万张图像作为数据集。

Implementation
文章网络使用 的图像进行训练,在训练阶段,作者渲染 的图像块,对于只包含背景的图像块直接丢弃。对每个训练样本采样 512 个来自表面、表面附近和整个空间的采样点,采样点使用固定焦距的 透视相机模型 投影到特征图上。
Results
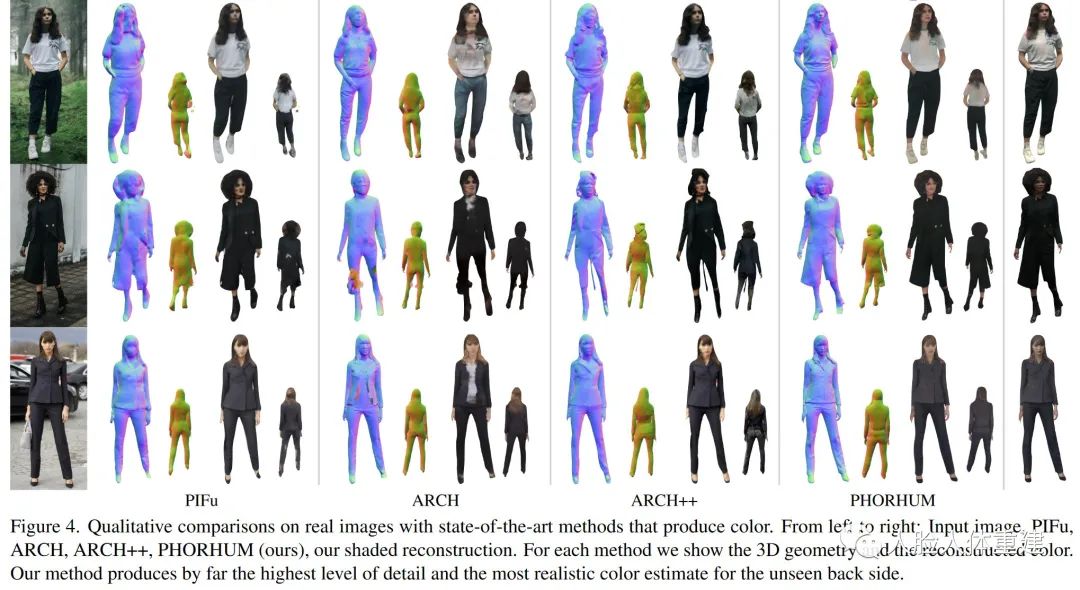
下图展示了文章方法和 PIFu、ARCH、ARCH++ 方法的结果对比。
下图展示了文章方法与 PIFuHD 的结果比较,文章方法能够重建差不多的表面细节,但会产生更少的噪声,而且文章方法还能重建人体的反照率。此外,由于文章方法使用的透视相机模型,其重建的结果更加自然,不像 PIFuHD 一样重建的头部偏大。

参考
-
Photorealistic Monocular 3D Reconstruction of Humans Wearing Clothing. Thiemo Alldieck, Mihai Zanfir, Cristian Sminchisescu. CVPR, 2022.
-
Fourier Features Let Networks Learn High Frequency Functions in Low Dimensional Domains. Matthew Tancik, Pratul P. Srinivasan, Ben Mildenhall, Sara Fridovich-Keil, Nithin Raghavan, Utkarsh Singhal, Ravi Ramamoorthi, Jonathan T. Barron, Ren Ng. NeurIPS, 2020.
-
Multiview Neural Surface Reconstruction by Disentangling Geometry and Appearance. Lior Yariv, Yoni Kasten, Dror Moran, Meirav Galun, Matan Atzmon, Ronen Basri, Yaron Lipman. NeurIPS, 2020.
本文仅做学术分享,如有侵权,请联系删文。
3D视觉工坊精品课程官网:3dcver.com
1.面向自动驾驶领域的多传感器数据融合技术
2.面向自动驾驶领域的3D点云目标检测全栈学习路线!(单模态+多模态/数据+代码) 3.彻底搞透视觉三维重建:原理剖析、代码讲解、及优化改进 4.国内首个面向工业级实战的点云处理课程 5.激光-视觉-IMU-GPS融合SLAM算法梳理和代码讲解 6.彻底搞懂视觉-惯性SLAM:基于VINS-Fusion正式开课啦 7.彻底搞懂基于LOAM框架的3D激光SLAM: 源码剖析到算法优化 8.彻底剖析室内、室外激光SLAM关键算法原理、代码和实战(cartographer+LOAM +LIO-SAM)
9.从零搭建一套结构光3D重建系统[理论+源码+实践]
10.单目深度估计方法:算法梳理与代码实现
11.自动驾驶中的深度学习模型部署实战
12.相机模型与标定(单目+双目+鱼眼)
13.重磅!四旋翼飞行器:算法与实战
14.ROS2从入门到精通:理论与实战
15.国内首个3D缺陷检测教程:理论、源码与实战
重磅!3DCVer-学术论文写作投稿 交流群已成立
扫码添加小助手微信,可申请加入3D视觉工坊-学术论文写作与投稿 微信交流群,旨在交流顶会、顶刊、SCI、EI等写作与投稿事宜。
同时也可申请加入我们的细分方向交流群,目前主要有3D视觉、CV&深度学习、SLAM、三维重建、点云后处理、自动驾驶、多传感器融合、CV入门、三维测量、VR/AR、3D人脸识别、医疗影像、缺陷检测、行人重识别、目标跟踪、视觉产品落地、视觉竞赛、车牌识别、硬件选型、学术交流、求职交流、ORB-SLAM系列源码交流、深度估计等微信群。
一定要备注:研究方向+学校/公司+昵称,例如:”3D视觉 + 上海交大 + 静静“。请按照格式备注,可快速被通过且邀请进群。原创投稿也请联系。

▲长按加微信群或投稿

▲长按关注公众号
3D视觉从入门到精通知识星球:针对3D视觉领域的视频课程(三维重建系列、三维点云系列、结构光系列、手眼标定、相机标定、激光/视觉SLAM、自动驾驶等)、知识点汇总、入门进阶学习路线、最新paper分享、疑问解答五个方面进行深耕,更有各类大厂的算法工程人员进行技术指导。与此同时,星球将联合知名企业发布3D视觉相关算法开发岗位以及项目对接信息,打造成集技术与就业为一体的铁杆粉丝聚集区,近4000星球成员为创造更好的AI世界共同进步,知识星球入口:
学习3D视觉核心技术,扫描查看介绍,3天内无条件退款

圈里有高质量教程资料、答疑解惑、助你高效解决问题
觉得有用,麻烦给个赞和在看~


