作者丨Clark@知乎
来源丨https://zhuanlan.zhihu.com/p/479534098
编辑丨3D视觉工坊
论文信息@article{teed2021droid,
title={Droid-slam: Deep visual slam for monocular, stereo, and rgb-d cameras},
author={Teed, Zachary and Deng, Jia},
journal={Advances in Neural Information Processing Systems},
volume={34},
year={2021}
}
论文与代码
https://arxiv.org/pdf/2108.10869.pdf
https://github.com/princeton-vl/DROID-SLAM
摘要 Abstract我们介绍一种新的基于深度学习的SLAM系统,DROID-SLAM,其包括通过一个Dense BA层反复迭代更新相机位姿和像素深度。这个系统是精确的,比之前的工作取得了大的提升,并且是鲁棒的,遭受灾难性失败要少得多。尽管在单目视频上进行训练,但它可以利用双目立体或RGB-D视频在测试时达到更好的性能。
1. 引言 IntroductionSLAM旨在(1)构建一个环境地图,(2)在这个环境中定位智能体。这是SFM运动恢复结构的一种特殊形式,专注于准确跟踪长期轨迹。对于机器人,特别是自主车辆,来说是一项关键的能力。在本文工作中,我们解决视觉SLAM问题,其中传感器以单目、双目或者RGBD相机捕获的图像形式进行录制。
SLAM问题已从许多不同角度进行处理。早期的工作使用基于概率和滤波器的方法,以及交替优化地图和相机位姿。再进一步,现代SLAM系统已经利用了最小二乘优化。准确度的一个重要元素是全局BA,其在一个单独的优化问题中联合优化相机位姿与3D地图。基于优化的形式的优势是SLAM系统能很容易的修改为使用不同的传感器。例如,ORBSLAM3支持单目、双目、RGBD以及IMU传感器,而且现代SLAM系统能够支持不同的相机模型。尽管取得了重大的进展,但是当前的SLAM系统对于许多真实世界的应用缺乏所需要的鲁棒性。在许多情况下会失效,例如特征点跟踪丢失,优化问题发散无法收敛以及偏移累积。深度学习已经被提出作为许多这些失效案例的解决方案。之前的工作已经研究了用神经3D表示学习到的特征来代替人工特征,并将学习的能量项与经典的后端优化进行结合。其它的工作尝试学习端到端的SLAM或者VO系统。虽然这些系统有时会很鲁棒,但它们在普通基准测试benchmark上的准确性远远低于经典SLAM系统。
本文提出DROID-SLAM,一种基于深度学习的新SLAM系统。它具有最佳的性能,在具有挑战性的基准测试上优于已有经典的或者是基于学习的SLAM系统。特别地,DROID-SLAM具有如下优点:
-
高准确性 High Accuracy:我们在多个数据集或者相机模式上取得比之前工作较大的提升。在TartanAir SLAM竞赛中,我们在单目跟踪上比之前最好地结果减少了62%的错误,在双目跟踪上减少60%。我们在ETH-3D RGBD SLAM榜单上排名第一,在AUC指标上比第二名要好35%,这包含了灾难性失效的误差以及比率。在EuRoC的单目数据集上,在零失败的方法中,我们减少了82%的误差。考虑到11个序列中只有10个成功了,它比ORB-SLAM3高出43%。使用双目相机的输入,我们比ORB-SLAM3减少了71%的误差。在TUM-RGBD数据集上,我们在零失败的方法中减少了83%的误差。
-
高鲁棒性 High Robustness:与以前的系统相比,我们发生的灾难性故障要少得多。在ETH-3D数据集上,我们成功地跟踪了32个RGB-D数据集中的30个,而第二名只成功地跟踪了19/32。关于TartanAir,EuRoC和TUM-RGBD数据集上,我们没有出现任何失效。
-
强泛化性 Strong Generalization:我们的系统只使用单目输入进行训练,可以直接使用双目或RGB-D输入来提高精度,而不需要再进行任何训练。我们在4个数据集和3种相机模式上的所有结果都是通过单一模型得到,完全在synthetic TartanAir数据集上,只用单目输入训练了一次。
DROID-SLAM的“可微循环优化启发设计 Differentiable Recurrent Optimization-Inspired Design(DROID)”使得其具有较强的性能和泛化性,是一个端到端可微的架构,它结合了经典方法和深度网络的优势。具体来说,它包括循环迭代更新,建立在光流的RAFT基础上,但引入了两个关键的创新点。
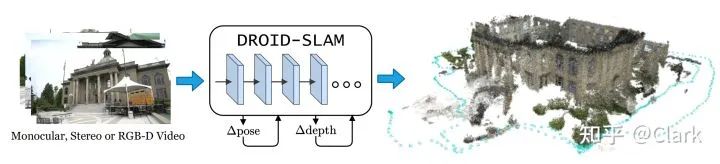
图1. DROID-SLAM可以在单目、双目和RGB-D视频上运行。它建立一个稠密的环境地图,同时在地图中定位相机。
首先,与迭代地更新光流的RAFT不同,我们迭代地更新相机位姿和深度。RAFT可以在两帧上运行,而我们的更新则可以应用于任意数量的帧,实现了所有相机位姿和深度图的联合全局优化,这对于最小化长轨迹和闭环的漂移至关重要。
其次,DROID-SLAM中相机位姿和深度图的每次更新都是由可微的Dense BA层产生的,该层计算出对相机位姿和每个像素的稠密深度dense per-pixel depth的高斯-牛顿更新,使其最大限度地提高其与当前光流估计的兼容性。这种DBA层利用了几何约束,提高了精度和鲁棒性,并使得单目系统可处理双目或RGB-D输入,而无需再次训练。
DROID-SLAM的设计是新颖的。之前最接近的深度架构是DeepV2D和BA-Net,这两种方法都专注于深度估计,并报告了有限的SLAM结果。DeepV2D 交替更新深度和更新相机位姿,而不是BA。BA-Net有一个BA层,但它们的层有本质上的不同:它不是“dense密集的”,因为它优化了一个用于线性组合深度基(一组预先预测的深度图)的少量系数,而我们直接对每个像素深度进行了优化,而不受深度基depth basis的阻碍。此外,BA-Net优化了光度重投影误差(在特征空间中),而我们优化了几何误差,利用了最先进的流估计flow estimation。
我们对四个不同的数据集和三种不同的相机模式进行了广泛的评估,在所有情况下都展示了最好的性能。我们还包括了消融实验,阐明了重要的设计决策和超参数。
2. 相关工作 Related Work现代SLAM系统将定位与建图视为一个联合优化问题。
视觉VSLAM专注于以单目、立体或RGB-D图像的形式进行观测。这些方法通常被分为直接法(direct)或间接法(indirect)。间接法首先通过检测感兴趣点将图像处理为中间表示(intermediate representation)和附加的特性描述子。然后在图像之间进行特征匹配。间接法通过最小化投影三维点与其在图像中的位置之间的重投影误差,来优化相机位姿和三维点云。
直接法对图像形成过程(image formation process)进行建模,并定义了一个光度误差上的目标函数。直接法的一个优点是,它们可以建模出图像的更多信息,如线和强度变化,这些不在间接法中使用。然而,光度误差通常会导致更困难的优化问题,并且直接法对卷帘快门伪影(rolling shutter artifacts)等几何失真的鲁棒性较差。这种方法需要更复杂的优化技术,如从粗到细的图像金字塔(coarse-to-fine image pyramid),以避免陷入局部最优。
我们的方法并不适合于上述任何一个类别。与直接法一样,我们不需要预处理步骤来检测和匹配图像之间的特征点。相反,我们使用完整的图像,允许我们利用比通常只使用角点和边缘特征的间接法更大、更广泛的信息。然而,类似于间接法,我们也最小化重投影误差。这是一个更容易的优化问题,并避免了需要更复杂的表示,如图像金字塔。从这个意义上说,我们的方法借鉴了两种方法的优点:间接法更平滑的目标函数和直接法更大的建模能力。
深度学习已经被广泛应用于SLAM问题。许多工作都集中于针对特定子问题的训练系统,如特征检测、特征匹配和离群值去除(outlier rejection)和定位。SuperGlue旨在进行特征匹配和验证,使二视图位姿估计更加鲁棒。我们的网络也从Dusmanu等人那里获得灵感,它建立一个神经网络到运动恢复结构SFM管线中,以提高关键点定位精度。
其他的工作都集中在端到端训练SLAM系统上。这些方法并不是完整的SLAM系统,而是专注于2帧到多大十几帧达的小规模重建。它们缺乏现代SLAM系统的许多核心能力,如闭环检测和全局BA集束调整,这抑制了它们执行大规模重建的能力,如我们实验中所示。∇SLAM实现了几种现有的SLAM算法作为可微计算图(differentiable computation graphs),允许将重建中的误差反向传播回传感器观测。而这个方法是可微的,它没有可训练的参数,这意味着系统的性能受到它们所模拟的经典算法精度的限制。
DeepFactors是最完整的深度SLAM系统,建立在早期的CodeSLAM之上。它可以对位姿和深度变量进行联合优化,并能够进行短期和远距离闭环。与BA-Net类似,DeepFactors在推理过程中优化了学习到的深度基(deep basis)的参数。相比之下,我们并不依赖于学习的basis,而是优化像素级的深度。这允许我们的网络更好地推广到新的数据集,因为我们的深度表示(depth representation)跟训练数据集不会绑定。
3. 方法 Approach我们将视频作为输入,有两个目标:估计相机的轨迹并建立环境的三维地图。我们首先描述单目相机的配置;在3.4小节描述如何将系统推广泛化到双目立体和RGB-D视频。

从添加到系统中的每个新图像中提取特征。这个阶段的关键组成部分借鉴了RAFT。
特征提取 Feature Extraction。每个输入的图像都通过一个特征提取网络进行处理。该网络由6个残差块和3个降采样层组成,产生1/8输入图像分辨率的稠密特征图。与RAFT一样,我们使用两个独立的网络:特征网络(feature network)和上下文网络(context network)。特征网络用于构建相关性体积集合(set of correlation volumes),而在更新操作符的每个应用期间,上下文特征都被注入到网络中。


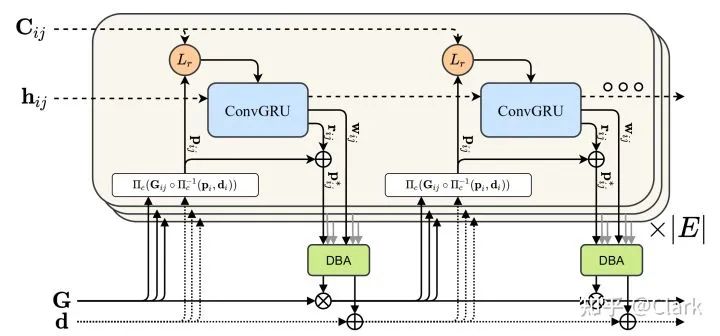
图2. 更新算子的图示。算子作用于frame-graph中的边上,预测通过(DBA)层映射到深度和位姿更新的流
 更新 Update。相关性特征和流特征在注入GRU之前分别通过两个卷积层进行映射。此外,我们还将由上下文网络提取的上下文特征,通过逐元素相加注入到GRU中。
更新 Update。相关性特征和流特征在注入GRU之前分别通过两个卷积层进行映射。此外,我们还将由上下文网络提取的上下文特征,通过逐元素相加注入到GRU中。
ConvGRU是一种具有较小感受野的局部操作运算。我们通过在图像的空间维度上平均隐藏状态来提取全局上下文,并使用这个特征向量作为附加输入到GRU中。全局上下文在SLAM中很重要,因为导致的不正确的一致性可能会降低系统的准确性。这对网络识别和拒绝错误的一致性非常重要。


我们的SLAM系统是在PyTorch中实现的,我们使用LieTorch的扩展版本在所有组元素(group elements)的切线空间中执行反向传播。
消除自由度 Removing gauge freedom。在单目设置下,网络只能恢复相机的轨迹到相似变换(similarity transform)。一个解决方案是定义一个对相似变换不变的损失。然而,在训练过程中仍然存在gauge-freedom,这对线性系统的调节和梯度的稳定性影响较小。我们通过将前两个位姿固定到每个训练序列的位姿真值上来解决这个问题。固定第一个位姿消除了六自由度的gauge freedom。固定第二个位姿可以解决尺度自由度(scale freedom)。
构建训练视频 Constructing training video。每个训练示例都由一个7帧的视频序列组成。为了确保稳定的训练和良好的下游性能,我们希望对不太容易或不太困难的视频进行采样。

在推理过程中,我们将网络组合成一个完整的SLAM系统。该SLAM系统以一个视频流作为输入,并实时进行重建和定位。我们的系统包含两个异步运行的线程。前端(front end)线程接受新的帧,提取特征,选择关键帧,并执行局部BA。后端(back end)线程同时在关键帧的整个历史记录上执行全局BA。我们在这里提供了该系统的概述。
初始化 Initialization。DROID-SLAM的初始化很简单。我们只是采集帧数据,直到我们有一组12个。当我们积累帧时,我们只保留了光流大于16px时的历史帧(通过应用一次更新迭代进行估计)。一旦积累了12帧,我们通过在3个时间步内的关键帧之间创建一条边来初始化一个frame-graph,然后运行10次迭代更新算子。
前端 Frontend。前端直接在输入的视频流上运行。它维护一个关键帧集合和一个frame graph,存储共视关键帧之间的边。关键帧的位姿和深度都是积极的被优化。首先从输入的帧中提取特征。然后将新帧添加到帧-图frame-graph中,通过平均光流测量添加具有3个最近邻的边。这个位姿使用线性运动模型进行初始化。然后,我们应用更新算子的几次迭代来更新关键帧的位姿和深度。我们固定前两个位姿,以消除测量自由度(gauge freedom),但将所有深度作为自由变量。
在跟踪到新帧后,我们选择一个关键帧进行删除。我们通过计算平均光流大小来计算帧对之间的距离,并去除冗余帧。如果没有帧是候选删除帧,我们就删除最旧的关键帧。

然后,我们将更新算子应用于整个frame-graph中,通常由数千个帧和边组成。存储完整的相关性体积集合将很快超过视频内存。相反,我们使用了在RAFT中提出的内存效率实现。
在训练过程中,我们在PyTorch中利用自动微分引擎(automatic differentiation engine)实现了稠密集束调整DBA。在推理时,我们使用了一个自定义的CUDA内核,它利用了block-sparse结构,然后对简化的相机块进行稀疏Cholesky分解。
我们只对关键帧图像执行全局BA。为了恢复非关键帧的位姿,我们通过迭代估计每个关键帧和它相邻的非关键帧之间的流来进行纯运动BA。在测试过程中,我们评估了完整的相机轨迹,而不仅仅是关键帧。
双目立体和RGBD。我们的系统可以很容易地修改为双目和RGBD视频。在RGB-D情况下,我们仍然将深度视为一个变量,因为传感器的深度可能是有噪声的,并且缺少观测结果,并且简单地添加一项到优化目标中(公式4),它用来惩罚观测深度和预测深度之间的平方距离。对于双目的情况,我们使用上面描述的完全相同的系统,只有两倍的帧图像,并固定DBA层中左右帧之间的相对位姿。帧图中的交叉相机边(cross camera edges)允许我们利用双目立体信息。
3D缺陷检测视频教程:国内首个3D缺陷检测教程:理论、源码与实战
4. 实验 Experiments我们在不同的数据集和传感器模态上进行了实验。我们与基于深度学习的和已建立的经典SLAM算法进行了比较,并特别强调了跨数据集的泛化。根据之前的工作,我们评估了相机轨迹的准确性,主要使用绝对轨迹误差(Absolute Trajectory Error,ATE)。虽然一些数据集有真值点云,但它们没有比较SLAM系统直接给出的三维重建的标准协议,因为SLAM系统可以选择要重建的三维点。评估稠密的三维重建是典型的在多视图立体几何领域内考虑的,超出了本工作的范围。

图3. DROID-SLAM可以推广到新的数据集。为此,我们展示了来自Tank & Temple、ScanNet、Sintel和ETH-3D上的结果;都使用单目视频。
我们的网络完全是由合成的Tartan Air数据集的单目视频训练而来的。我们训练我们的网络250k步,批量大小为4,分辨率为384×512,7个帧剪辑,展开15次更新迭代。在4个RTX-3090 GPU上进行训练花费了1周时间。
TartanAir(单目和双目)该数据集是一个具有挑战性的综合基准测试,并被用作ECCV 2020 SLAM competition的一部分。我们使用official test split,并在表1中提供所有“Hard”序列的ATE。

表1. 在TartanAir单目基准上的结果
表1证明了我们的方法的鲁棒性(没有灾难性的故障)和准确性(非常低的漂移)。我们在TartanAir上重新训练DeepV2D作为基线baseline。在大多数序列上,我们的表现都优于现有的方法有一个数量级,其平均误差比TartanVO低8倍,比DeepV2D低20倍。在表2中,我们还使用TartanAir数据集与ECCV 2020 SLAM竞赛中排名前几的结果进行比较。竞赛中排前两位的使用系统COLMAP构建的系统,并且速度要比实时运行慢40倍。另一方面,我们的方法在单目基准上的运行速度提高了16倍,在单目基准上的误差降低了62%,在双目基准上降低了60%。
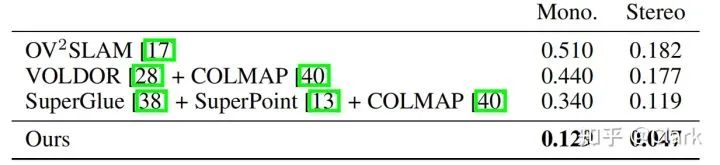
表2. 在TartanAir测试集上的结果,与ECCV2020 SLAM竞赛上前3名的对比。分数是使用归一化相对位姿误差进行计算的,对于所有可能的长度的序列{5、10、15,...,40}米。
EuRoC(单目和双目)在剩下的实验中,我们感兴趣的是我们的网络泛化到新的相机和环境的能力。EuRoC数据集包括从微型飞行器(MAV)上的传感器捕获的视频,是广泛用于评估SLAM系统的基准。我们使用EuRoC数据集来评估单目和双目的性能,并表3中报告了结果。
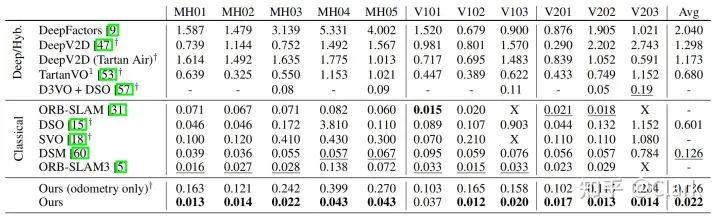
表3. EuRoC数据集上的单目SLAM, ATE[m]表示视觉里程计方法。
在单目配置下,我们实现了平均2.2cm的ATE,在零失败的方法中减少了82%,在仅比较ORB-SLAM3成功的序列时,比ORB-SLAM3减少了43%。
我们与几种深度学习方法进行比较。我们将在TartanAir数据集上训练的DeepV2D和在NYUv2和ScanNet上训练的公开版本进行了比较。DeepFactors是在ScanNet上训练的。我们发现,与经典的SLAM系统相比,最近的深度学习方法在EuRoC数据集上表现不佳。这是由于糟糕的泛化能力和数据集偏差导致大量的漂移;我们的方法没有这些问题。D3VO通过将神经网络作为前端与DSO作为后端相结合,能够获得良好的鲁棒性和准确性,使用11个序列中的6个进行评估,并对其余的序列进行无监督训练,其中包含用于评估的相同场景。
TUM-RGBD数据集。RGBD数据集由用手持相机拍摄的室内场景组成。由于卷帘快门伪影,运动模糊以及剧烈的旋转,这是一个非常困难的单目方法数据集。在表4中,我们对整个Freiburg1数据集进行了基准测试。
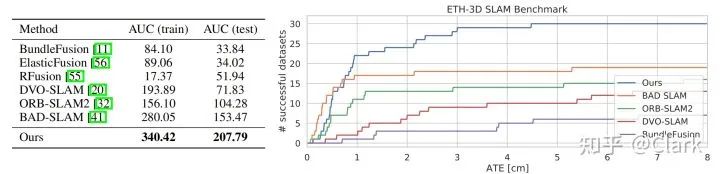
图4. 在RGB-D ETH3D-SLAM基准测试上的泛化结果。(左)我们方法,只在合成的TartanAir数据集上进行训练,在训练和测试划分上都排第一。(右)成功轨迹个数作为ATE的函数图。我们的方法成功地跟踪了30/32个RGBD图像数据。
经典的SLAM算法,如ORB-SLAM,往往在大多数序列上失败。虽然深度学习方法更鲁棒,但它们对大多数评估序列的精度较低。我们的方法既鲁棒又准确。它成功地跟踪了所有9个序列,同时ATE绝对轨迹误差比DeepFactor低83%,在所有视频上都成功,ATE比DeepV2D低90%。
ETH3D-SLAM (RGBD) 最后,我们在ETH3D-SLAM基准测试上评估了RGB-D的性能。在这个设置中,网络还提供了RGB-D相机的测量。我们把我们的网络在TartanAir上进行训练,并在优化目标中添加一个加法项,惩罚预测的逆深度和传感器观测的深度之间的距离。没有任何微调,我们的方法在训练和测试集上均排名第一。其中一些数据集是“暗”的,这意味着没有图像数据;在这些数据集上,我们不提交任何预测。在测试集上,我们成功地跟踪了30/32 RGB-D。
时间和内存效率(Timing and Memory)。我们的系统可以用2个3090 GPU实时运行。跟踪和局部BA在第一个GPU上运行,而全局BA和闭环检测在第二个GPU上运行。在EuRoC数据集上,我们以平均20帧每秒(相机帧率)降采样到320×512分辨率,跳过每一帧。表3中的结果是在这个配置下得到的。在TUM-RGBD数据集上,我们通过降采样到240×320并跳过其他每一帧。在TartanAir数据集上,由于相机运动更快,我们无法实时运行,平均8帧每秒。然而,这仍然是TartanAirSLAM挑战的16倍,其依赖于COLMAP。
SLAM前端可以在具有8 GB内存的GPU上运行。后端需要存储全套图像数据集的特征图,内存上更紧张。TUM-RGBD数据集上的所有结果都可以在单个1080 Ti显卡上产生。EuRoC、TartanAir和ETH-3D(视频可以达5000帧)数据集上的结果需要一个24GB内存的GPU。而内存和资源的需求目前是我们的系统最大的限制,我们相信这些可以通过剔除冗余计算和更有效的表示来大大减少。
5. 总结 Conclusion我们介绍了DROID-SLAM,一种用于视觉SLAM的端到端神经结构。DROID-SLAM是准确的、鲁棒的和通用的,可用于单目、双目和RGB-D视频。在具有挑战性的基准测试上,它的表现大幅优于之前的工作。
本文仅做学术分享,如有侵权,请联系删文。
3D视觉工坊精品课程官网:3dcver.com
1.面向自动驾驶领域的多传感器数据融合技术
2.面向自动驾驶领域的3D点云目标检测全栈学习路线!(单模态+多模态/数据+代码) 3.彻底搞透视觉三维重建:原理剖析、代码讲解、及优化改进 4.国内首个面向工业级实战的点云处理课程 5.激光-视觉-IMU-GPS融合SLAM算法梳理和代码讲解 6.彻底搞懂视觉-惯性SLAM:基于VINS-Fusion正式开课啦 7.彻底搞懂基于LOAM框架的3D激光SLAM: 源码剖析到算法优化 8.彻底剖析室内、室外激光SLAM关键算法原理、代码和实战(cartographer+LOAM +LIO-SAM)
9.从零搭建一套结构光3D重建系统[理论+源码+实践]
10.单目深度估计方法:算法梳理与代码实现
11.自动驾驶中的深度学习模型部署实战
12.相机模型与标定(单目+双目+鱼眼)
13.重磅!四旋翼飞行器:算法与实战
14.ROS2从入门到精通:理论与实战
15.国内首个3D缺陷检测教程:理论、源码与实战
重磅!3DCVer-学术论文写作投稿 交流群已成立
扫码添加小助手微信,可申请加入3D视觉工坊-学术论文写作与投稿 微信交流群,旨在交流顶会、顶刊、SCI、EI等写作与投稿事宜。
同时也可申请加入我们的细分方向交流群,目前主要有3D视觉、CV&深度学习、SLAM、三维重建、点云后处理、自动驾驶、多传感器融合、CV入门、三维测量、VR/AR、3D人脸识别、医疗影像、缺陷检测、行人重识别、目标跟踪、视觉产品落地、视觉竞赛、车牌识别、硬件选型、学术交流、求职交流、ORB-SLAM系列源码交流、深度估计等微信群。
一定要备注:研究方向+学校/公司+昵称,例如:”3D视觉 + 上海交大 + 静静“。请按照格式备注,可快速被通过且邀请进群。原创投稿也请联系。

▲长按加微信群或投稿

▲长按关注公众号
3D视觉从入门到精通知识星球:针对3D视觉领域的视频课程(三维重建系列、三维点云系列、结构光系列、手眼标定、相机标定、激光/视觉SLAM、自动驾驶等)、知识点汇总、入门进阶学习路线、最新paper分享、疑问解答五个方面进行深耕,更有各类大厂的算法工程人员进行技术指导。与此同时,星球将联合知名企业发布3D视觉相关算法开发岗位以及项目对接信息,打造成集技术与就业为一体的铁杆粉丝聚集区,近4000星球成员为创造更好的AI世界共同进步,知识星球入口:
学习3D视觉核心技术,扫描查看介绍,3天内无条件退款

圈里有高质量教程资料、答疑解惑、助你高效解决问题
觉得有用,麻烦给个赞和在看~


