
点击上方“3D视觉工坊”,选择“星标”
干货第一时间送达

作者丨paopaoslam
来源丨泡泡机器人SLAM
标题: ORB-SLAM with Near-infrared images and Optical Flow data
作者: Patrick Ruhkamp, Daoyi Gao, Hanzhi Chen, Nassir Navab, Benjamin Busam
机构: TUM
来源: 3DV 2021
编译: zhuhu
审核: zh
论文:https://arxiv.org/pdf/2110.08192v1.pdf
code:https://daoyig.github.io/attention_meets_geometry/
译者总结将时间和空间的注意力机制相结合,解决了很多在时间,空间上的不一致性问题。
摘要对于自监督单目深度预测框架来说,在时间上连续的图像上推断几何一致的密集3D场景仍然是具有挑战性的。本文探讨了日益流行的transformer框架,结合新颖的正则化的损失函数,如何在保持精度的同时提高深度一致性。我们提出了一个空间注意模块,它将粗略的深度预测与聚合局部几何信息相关联。一种新的时间注意机制进一步处理跨连续图像的全局上下文中的局部几何信息。此外,我们还引入了由光度循环一致性正则化的帧之间的几何约束。通过将我们提出的正则化和新的时空注意模块相结合,我们充分利用了单目框架之间的几何和基于外观的一致性。与以前的方法相比,这产生了几何意义上的注意力机制,并提高了时间深度、稳定性和准确性。
主要工作与贡献在自监督的方法中,强制几何一致性约束通常会对模糊和平滑深度间断的深度精度产生负面影响。我们提出了时间一致性深度估计框架,称为TC-Depth。能够在时空注意力机制中显式学习用于深度估计的时间一致性,以及几何正则化,从而得到高准确度和前所未有的一致性。另外是消融实验也证明了在一致性和准确性上单独模块的贡献,和我们光度循环一致性和新颖的几何一致性是怎样显著提高注意力机制的。我们的贡献如下:
-
一项新的聚焦局部几何信息的空间注意力机制。
-
一种跨单目相机帧之间的时间注意力机制来保证全局一致性。
-
一种新的特征嵌入时空注意力机制融合几何制导的循环一致性正则化方案。
-
一种新的跨帧之间的时间一致性矩阵来确保深度一致性。
TC-Depth的目标是以自监督的方式从单目图像序列中学习一致和准确的深度。我们联合使用了广泛使用的回归深度和相对相机姿势的范例,通过用预测的密集深度和姿势向后翘曲将相邻帧扭曲到共同的中心视图后,使图像重建损失最小化。
框架如下图所示,在位姿回归方面,使用的是和之前工作一样的策略[15,43]. 之后是对特征编码器进行拓展,用于匹配在bottleneck中的attention模块中的像素。编码器中的特征嵌入也额外增加了辅助单尺度深度解码器,该辅助单尺度深度解码器为时空注意模块产生的粗略的初始深度估计。
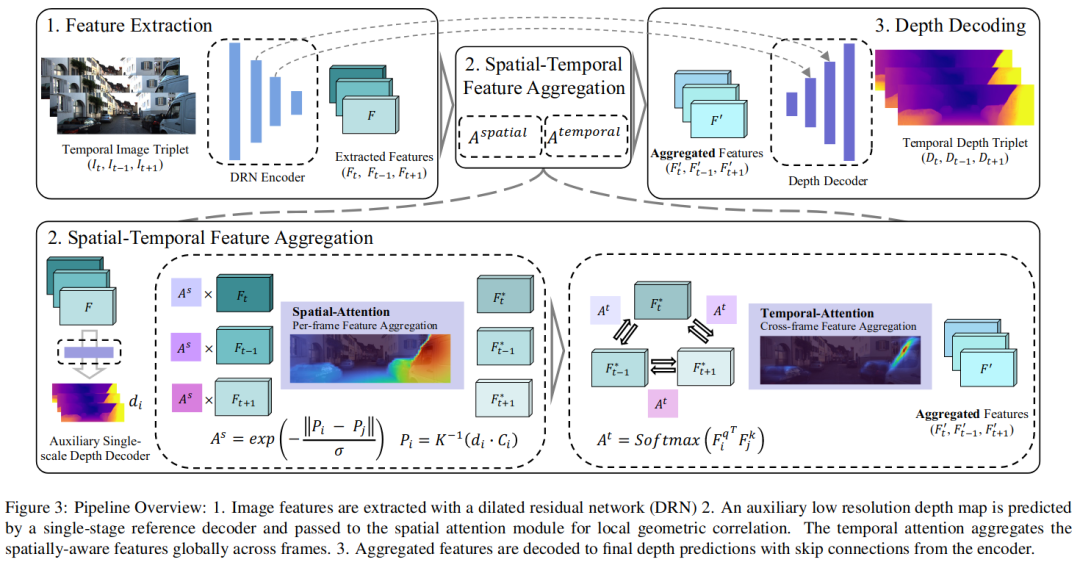
受光流方法的启发,在经过最终的深度解码器之前,将编码的输入特征与空间注意力机制一起聚集时间上一致的场景内容。
注意力机制卷积神经网络受感受野的约束,禁止从空间长距离输入特征相关连。Transformers在NLP中提出,用来关联那些有一定语义相关性但是在句子结构上相距甚远的句项。注意力机制的定义如下:

近期的transformers和自注意力和交叉注意力的性能已经完全优于CNN,通过这些得到了我们的时空注意力模块。
空间注意力层在[23]中提出的自我注意将同一图像中的信息关联起来,以注意场景中视觉上相似的部分。注意力模块中的点积可以从3D场景中几何距离较远的部分引入一些特征聚合,这可能不是稠密深度回归任务所需要的。
利用粗预测的初始深度估计来阐述有3D空间感知的自注意力模块。已知内参K和一对特征点坐标,和对应的深度。首先可以将像素反投影到3d空间。
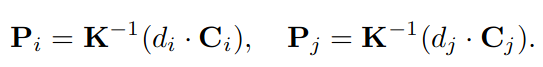
之后则可以将空间注意力阐述为:

其中可以看作是key和query。这里可以解释为通过3D空间相关性的3D位置编码。
时间注意力层受到光流关联层和最近稠密匹配的启发,通过自监督训练方案的时间图像序列输入,我们提出了一种新的跨帧时间注意力机制。因此,给出一组来自连续图像输入的三元组特征映射,我们可以迭代地选择其中一个作为查询,其余作为关键特征,然后使用Softmax获取关键查询相似度。则有如下定义:

我们提出的时空注意模型的独特形式可以明确地关联几何意义和空间连贯的特征-通过首先通过空间注意-同时提供跨后续帧的时间关联。图4分别可视化了查询像素的空间和时间注意力。空间注意力聚集了场景中几何上一致的部分(请注意,在对象边缘对背景的注意力梯度很大)。基于外表的时间注意将全局信息联系起来,这在朴素的方法中可能是困难和不精确的。使用我们的附加几何约束,注意力非常集中和空间连贯,就像两个非常有挑战性的例子所说明的那样,结构很薄,物体很动态。

如果在投影到同一摄影机视图后约束帧之间的绝对深度或视差值,则会缩小或放大整个场景深度比例。尺度不变性已经被提出,但是并不能为显示小对准误差的深度值提供强梯度。因此,我们在公式中加入了正则化的部分,用于限制帧间的深度预测。
从光度一致性得到循环掩膜聚合不同视图上的像素平均几何损失会违反场景结构,因为遮挡区域会影响损失计算,从而导致边缘模糊和深度精度降低。为了避免这个问题,已经提出了像素级最小深度误差。然而,定量和定性评估表明,该策略虽然主要解决了遮挡区域的问题,但通常也排除了场景中的主要区域。这些区域可能由于相邻深度图的不精确变换而具有很大的不一致性。最小操作符可以掩盖场景的大区域(见图5),这会损害训练信号。

取而代之的是,我们提出了一种新的掩蔽方案,该方案利用了照片一致性的假设。为此,将中心目标图像投影变换到相邻源帧的视图,然后再次变换回。则我们的循环掩膜可表示为:
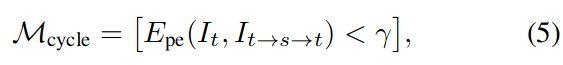
我们的模型是用一组基于内容的图像重建和深度图的几何特性的损失项来训练的。

手指去的启发,我们简化了自监督深度预测网络Monodepth2, 让其成为一个teacher,我们定义了一个掩膜,其中在预测和teacher之间区别较大的部分也许可以指明运动物体。之后会和光度误差相结合:

这个部分的运动一致性损失项能够帮助student模块从弱tracher学习,因为:

在图像之间的光度误差定义如下:
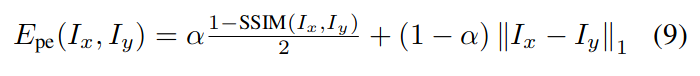
自动遮罩说明对象以与相机自我运动相同的速度和方向移动。
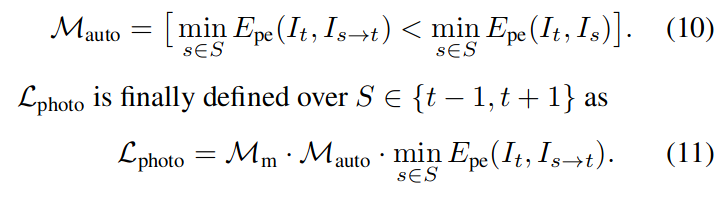
边缘感知顺滑度在之前的工作中一样,用均值归一化的逆深度作为局部平滑深度估计:
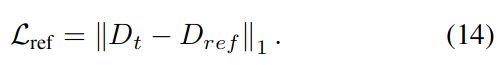
在之前提及的那种,我们设计了一种几何损失来鼓励帧之间一致的深度预测,这不仅缓解了深度预测尺度的惩罚问题,而且利用了循环一致性(Eq.。5)通过以下方式处理遮挡:

为了训练单阶段辅助深度解码器用于空间注意力机制的获取,我们将其与整个框架的最终深度预测的差异降低至最小:
我们建议在通过投影变换在3D中对齐多个k帧之后,直接测量预测深度输出的一致性,其中k被选择在{3,5,7}(对于室外驾驶场景,较长的序列通常没有足够的视觉重叠)。为了将来自的所有预测转换到它的公共参照系中,我们使用真实值深度和姿态。单目方法(具有尺度模糊性)首先与相同的中值尺度比对齐。我们的时间一致性度量(TCM)衡量估计的像素深度和多帧之间的GT之间的跟踪差异。


据我们所知,我们首次提出了一个充分利用时空域来预测自监督一致深度估计的模型,该模型引入了一个独特的、新颖的基于几何和外观信息的注意模型。我们的方法TC-Depth已经证明,几何约束和周期一致性正则化相结合,可以通过引导时空注意聚合来进一步提高这种一致性。未来时间一致性深度估计的研究现在可以客观地与新的时间一致性度量(TCM)进行比较。
Reference[15]Cl ́ ement Godard, Oisin Mac Aodha, Michael Firman, and Gabriel J Brostow. Digging into self-supervised monocular depth estimation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 3828–3838, 2019.
[43]Jamie Watson, Oisin Mac Aodha, Victor Prisacariu, Gabriel Brostow, and Michael Firman. The temporal opportunist: Self-supervised multi-frame monocular depth. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1164–1174, 2021.
如果你对本文感兴趣,请点击点击阅读原文下载完整文章。
本文仅做学术分享,如有侵权,请联系删文。
3D视觉工坊精品课程官网:3dcver.com
1.面向自动驾驶领域的多传感器数据融合技术
2.面向自动驾驶领域的3D点云目标检测全栈学习路线!(单模态+多模态/数据+代码) 3.彻底搞透视觉三维重建:原理剖析、代码讲解、及优化改进 4.国内首个面向工业级实战的点云处理课程 5.激光-视觉-IMU-GPS融合SLAM算法梳理和代码讲解 6.彻底搞懂视觉-惯性SLAM:基于VINS-Fusion正式开课啦 7.彻底搞懂基于LOAM框架的3D激光SLAM: 源码剖析到算法优化 8.彻底剖析室内、室外激光SLAM关键算法原理、代码和实战(cartographer+LOAM +LIO-SAM)
9.从零搭建一套结构光3D重建系统[理论+源码+实践]
10.单目深度估计方法:算法梳理与代码实现
11.自动驾驶中的深度学习模型部署实战
12.相机模型与标定(单目+双目+鱼眼)
13.重磅!四旋翼飞行器:算法与实战
14.ROS2从入门到精通:理论与实战
15.国内首个3D缺陷检测教程:理论、源码与实战
重磅!3DCVer-学术论文写作投稿 交流群已成立
扫码添加小助手微信,可申请加入3D视觉工坊-学术论文写作与投稿 微信交流群,旨在交流顶会、顶刊、SCI、EI等写作与投稿事宜。
同时也可申请加入我们的细分方向交流群,目前主要有3D视觉、CV&深度学习、SLAM、三维重建、点云后处理、自动驾驶、多传感器融合、CV入门、三维测量、VR/AR、3D人脸识别、医疗影像、缺陷检测、行人重识别、目标跟踪、视觉产品落地、视觉竞赛、车牌识别、硬件选型、学术交流、求职交流、ORB-SLAM系列源码交流、深度估计等微信群。
一定要备注:研究方向+学校/公司+昵称,例如:”3D视觉 + 上海交大 + 静静“。请按照格式备注,可快速被通过且邀请进群。原创投稿也请联系。

▲长按加微信群或投稿

▲长按关注公众号
3D视觉从入门到精通知识星球:针对3D视觉领域的视频课程(三维重建系列、三维点云系列、结构光系列、手眼标定、相机标定、激光/视觉SLAM、自动驾驶等)、知识点汇总、入门进阶学习路线、最新paper分享、疑问解答五个方面进行深耕,更有各类大厂的算法工程人员进行技术指导。与此同时,星球将联合知名企业发布3D视觉相关算法开发岗位以及项目对接信息,打造成集技术与就业为一体的铁杆粉丝聚集区,近4000星球成员为创造更好的AI世界共同进步,知识星球入口:
学习3D视觉核心技术,扫描查看介绍,3天内无条件退款

圈里有高质量教程资料、答疑解惑、助你高效解决问题
觉得有用,麻烦给个赞和在看~

