
点击上方“3D视觉工坊”,选择“星标”
干货第一时间送达

作者丨大瓶子@知乎
来源丨https://zhuanlan.zhihu.com/p/547183305
编辑丨3D视觉工坊
宣传一下我们ACM MM 2022的论文:You Only Hypothesize Once: Point Cloud Registration with Rotation-equivariant Descriptors。针对于点云配准任务,我们提出通过设计旋转等变的描述子,一方面可以解耦出更加可靠的旋转不变特征,另一方面可以实现一对同名点预测变换矩阵,进而大大减小RANSAC的检索空间,实现可靠的点云配准。
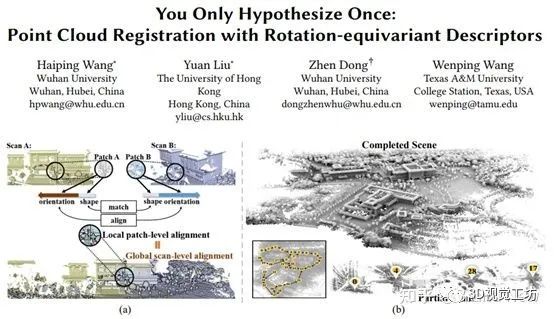
图1 (a)YOHO框架;(b)室外真实数据配准效果。
论文链接:https://arxiv.org/abs/2109.00182
代码链接:https://github.com/HpWang-whu/YOHO
项目主页:https://hpwang-whu.github.io/YOHO/
太长不看 TL; DR:我们提出了一种全新的基于局部旋转等变特征的点云配准框架,我们设计的描述子同时具有理论保证的旋转不变性及旋转等变性,其中旋转不变性可以用于同名点配对,而对任意一对同名点对,我们可以利用其旋转等变性直接获取点云之间的变换矩阵,这将RANSAC的立方级检索空间降低为线性检索空间,可以实现快速收敛。实验表明,YOHO仅利用1k次RANSAC迭代即可超过SOTA算法在50k次迭代的效果。
下面是详细介绍~ 1. 基于特征的点云配准:基于特征的点云配准首先在两帧点云上各提取一些关键点特征,随后基于特征相似性进行关键点配对确定一组同名关键点对,并通过RANSAC的策略克服其中误匹配的影响来得到最终的变换矩阵。
由于两帧点云存在未知SE(3)变换,所以所提取的关键点特征在各种姿态下保持不变以用于后续匹配。其中平移不变性是较好实现的,通过关键点中心化提取局部特征即可消除其影响。因此大量算法聚焦于构建描述能力强的旋转不变特征(SO(3) Invariance)。
2. 现有配准算法存在的问题?-
首先是旋转不变特征的构建不鲁棒或无理论保证。现有方法多利用构建局部参考框架(LRF)、数据增强、或人为构建旋转不变量等方式,对当前局部点云丢失掉其方向信息(旋转相关),仅编码形状信息(旋转无关)。但现有方法存在如下弊端,首先利用PCA算法等提取的局部参考框架很容易受到噪声,点密度分布的影响并且存在模糊性问题,而数据增强策略会降低特征的泛化能力,人为构建的旋转不变量则描述能力较弱。
-
其次是变换估计的立方级检索空间。利用旋转不变特性匹配得到同名点后,在RANSAC中,需要通过任意选取三对同名点,利用Kabsch算法才能解算一个变换矩阵用于验证,这导致RANSAC存在立方级的检索空间,换句话说,如果同名点的正确比例为10%(这是普遍存在的),一次Kabsch估计的变换矩阵的正确率仅为0.13=0.001,这会引入大量噪声同时收敛很慢,因此现有算法多利用50k次RANSAC迭代保证效果。
简单来说,我们保留了方向信息!如图1(a),不同以往,我们在特征中同时编码了方向信息和形状信息。其中方向信息体现为描述子的旋转等变性,形状信息表述为描述子的旋转不变性。基于此:
-
无需构建局部参考框架等,可以理论保证的解耦出形状信息(旋转不变)用于同名点匹配;
-
而对于一对同名点,通过对齐其方向信息,可以直接得到变换矩阵,将RANSAC检索空间降低为线性。直观上,当同名点对正确比例为10%时,一次估计得到的变换矩阵正确率将近似为0.1,大大减少噪声和加速收敛!
4.1 群描述子构建
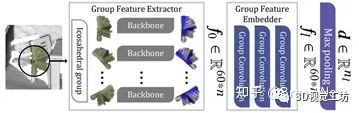
图2 描述子构建

4.2 群旋转等变性与旋转不变性

4.3 一对同名点解耦变换矩阵
除了消除旋转等变性来获取旋转不变特征,我们如何进一步利用旋转不变性呢?有了它,一对同名点就能估计变换矩阵。 对于一对同名点对的群描述子,我们利用其等变特性,检索能最佳对齐同名点群特征的行置换矩阵,得到其所对应的粗旋转(群元素):
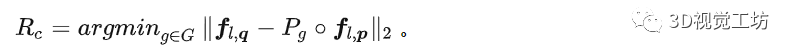
该粗旋转是群中与真实旋转最相近的群元素,而对于真实旋转与粗群旋转间的残差,我们可以利用特征粗对齐之后的残差进行回归:

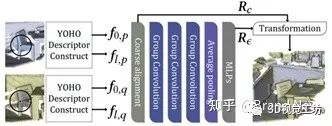
图3 单点对刚性变换估计
4.4 RANSAC 变体
至此,在各个同名点对上获得粗旋转和精准变换后,我们提出了两种RANSAC变体加速收敛。由于点云配准为刚性变换,各个局部变换(旋转,平移)及全局变换应一致,因此,(1)在传统算法Kabsch中选择三对点构建变换矩阵之前,我们增加三点选择条件为三对点估计的粗旋转应一{(i,j,k)|Rc,i=Rc,j=Rc,k}该条件可以快速剔除错误三点对,减少噪声、加速RANSAC收敛,记为YOHO-C。此外,(2) 我们可以直接丢弃Kabsch算法,转而直接利用每对点对估计的精准变换做RANSAC验证,这仅为RANSAC提供极少量的可靠验证集,即有多少同名点对,就仅有多少待验证变换,大大加速收敛速度,记为YOHO-O。
4.5 配准流程
讲到这里我们已经具备了进行配准的条件,基于此我们设计如下流程:

图4 YOHO流程
给定两帧待配准点云,我们首先根据4.2在两帧点云上分别提取一系列群描述子YOHO-Desc,其同时具有旋转不变性(pooling)和旋转等变性,利用其旋转不变部分我们进行基于特征相似性的特征配对得到一系列同名点对,而利用这些同名点对的旋转等变部分,根据4.3提出的算法可以对每对点对获得一个粗旋转及一个准确变换。我们将这些变换用于提出的RANSAC变体(4.4)进行验证得到最终的估计变换。
5. 效果如何?5.1 对比SOTA方法?

表1 3DMatch/3DLoMatch测试结果
其中预测的同名点对正确率即Inlier Ratio上YOHO取得了SOTA水平,证明群旋转不变的相较于现有旋转不变获取方式的优越性。而Registration Recall指标显示,所提出的变体YOHO-C/O,仅利用1k甚至0.1k次RANSAC迭代就取得了超过SOTA的水平(3DLoMatch上5%的提升),体现了旋转等变变换估计的有效性。此外值得注意的是,我们在没有利用点云间重叠信息的情况下,甚至超过了利用重叠信息增强同名点预测的Predator,体现了YOHO的可靠性。
5.2 泛化性?
仅在室内场景做训练,直接泛化到室外场景的ETH和WHU-TLS,YOHO也取得了SOTA效果,而现有算法多有大幅度效果下降,这得益于YOHO-Desc具有理论支撑的旋转不变性,克服了全空间旋转数据增强带来的对训练集的过拟合问题,同时具有比local-patch based算法如SpinNet等更快的计算:
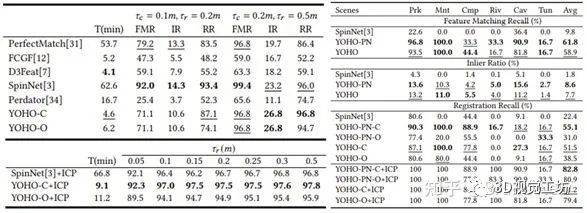
表2 (左)ETH泛化结果,(右)WHU-TLS泛化结果
5.3 消融实验?
我们通过消融实验验证了基于群的旋转不变性获取(id=1),群卷积设计(id=3)及利用旋转等变性估计变换(id=4)均对YOHO的表现起到重要作用,验证了我们设计的有效性:
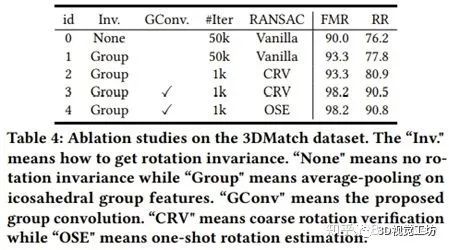
表3 消融实验
5.4 描述子可靠性?
除了实验[1]中所估计同名点对的正确率Inlier Ratio取得SOTA效果外,我们还进行了点密度及噪声的鲁棒性实验,发现群旋转不变性也能够更好的克服点密度及噪声的影响:
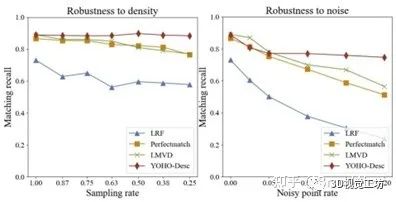
图5 旋转不变量鲁棒性实验
5.5 RANSAC收敛速度?等变用起来~
利用旋转等变性估计变换矩阵的收敛有多快呢?在3D(Lo)Match上不到400次迭代!更可靠 更高效~ 而现有基于旋转不变量的方法,特别是在较难的3DLoMatch上,需要远远更多的迭代。
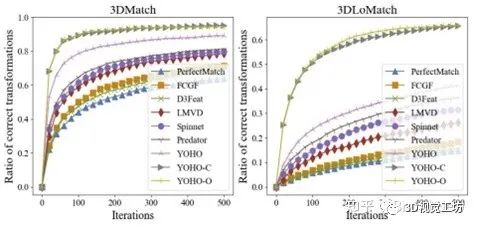
图6 变换估计收敛
6 相关文献1.Kabsch W. A solution for the best rotation to relate two sets of vectors[J]. Acta Crystallographica Section A: Crystal Physics, Diffraction, Theoretical and General Crystallography, 1976, 32(5): 922-923.
2.Choy C, Park J, Koltun V. Fully convolutional geometric features[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2019: 8958-8966.
3.Huang S, Gojcic Z, Usvyatsov M, et al. Predator: Registration of 3d point clouds with low overlap[C]//Proceedings of the IEEE/CVF Conference on computer vision and pattern recognition. 2021: 4267-4276.
4.Ao S, Hu Q, Yang B, et al. Spinnet: Learning a general surface descriptor for 3d point cloud registration[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021: 11753-11762.
本文仅做学术分享,如有侵权,请联系删文。
3D视觉工坊精品课程官网:3dcver.com
1.面向自动驾驶领域的多传感器数据融合技术
2.面向自动驾驶领域的3D点云目标检测全栈学习路线!(单模态+多模态/数据+代码) 3.彻底搞透视觉三维重建:原理剖析、代码讲解、及优化改进 4.国内首个面向工业级实战的点云处理课程 5.激光-视觉-IMU-GPS融合SLAM算法梳理和代码讲解 6.彻底搞懂视觉-惯性SLAM:基于VINS-Fusion正式开课啦 7.彻底搞懂基于LOAM框架的3D激光SLAM: 源码剖析到算法优化 8.彻底剖析室内、室外激光SLAM关键算法原理、代码和实战(cartographer+LOAM +LIO-SAM)
9.从零搭建一套结构光3D重建系统[理论+源码+实践]
10.单目深度估计方法:算法梳理与代码实现
11.自动驾驶中的深度学习模型部署实战
12.相机模型与标定(单目+双目+鱼眼)
13.重磅!四旋翼飞行器:算法与实战
14.ROS2从入门到精通:理论与实战
15.国内首个3D缺陷检测教程:理论、源码与实战
16.基于Open3D的点云处理入门与实战教程
重磅!3DCVer-学术论文写作投稿 交流群已成立
扫码添加小助手微信,可申请加入3D视觉工坊-学术论文写作与投稿 微信交流群,旨在交流顶会、顶刊、SCI、EI等写作与投稿事宜。
同时也可申请加入我们的细分方向交流群,目前主要有3D视觉、CV&深度学习、SLAM、三维重建、点云后处理、自动驾驶、多传感器融合、CV入门、三维测量、VR/AR、3D人脸识别、医疗影像、缺陷检测、行人重识别、目标跟踪、视觉产品落地、视觉竞赛、车牌识别、硬件选型、学术交流、求职交流、ORB-SLAM系列源码交流、深度估计等微信群。
一定要备注:研究方向+学校/公司+昵称,例如:”3D视觉 + 上海交大 + 静静“。请按照格式备注,可快速被通过且邀请进群。原创投稿也请联系。

▲长按加微信群或投稿

▲长按关注公众号
3D视觉从入门到精通知识星球:针对3D视觉领域的视频课程(三维重建系列、三维点云系列、结构光系列、手眼标定、相机标定、激光/视觉SLAM、自动驾驶等)、知识点汇总、入门进阶学习路线、最新paper分享、疑问解答五个方面进行深耕,更有各类大厂的算法工程人员进行技术指导。与此同时,星球将联合知名企业发布3D视觉相关算法开发岗位以及项目对接信息,打造成集技术与就业为一体的铁杆粉丝聚集区,近4000星球成员为创造更好的AI世界共同进步,知识星球入口:
学习3D视觉核心技术,扫描查看介绍,3天内无条件退款

圈里有高质量教程资料、答疑解惑、助你高效解决问题
觉得有用,麻烦给个赞和在看~

